Jak zmniejszyć rozmiar plików EXE/DLL tworzonych w środowisku DelphiPoradnik ten opisuje, jak należy pisać program, by stworzyć jak najmniejszy binarny plik wynikowy. Praktycznie wszyscy programujący w Delphi, gdy po raz pierwszy zetkną się z tym kompilatorem, są zszokowani rozmiarem powstałego pliku. W przypadku pustej formatki w środowisku Delphi XE2 jest to prawie 1MB plik EXE, a w przypadku programu 64 bitowego powstaje blisko 2MB binarka! Wtedy zaczyna się poszukiwanie odpowiedzi na pytanie: Co zrobić, aby zmniejszyć rozmiar pliku EXE/DLL w Delphi?
Często jednym z najbardziej efektywnych rozwiązań jest zastosowanie programu pakującego w locie (UPX). Rozwiązanie to ma sporo zalet, jednak w rzeczywistości program znajdujący się w pamięci wciąż jest duży, a rozpakowanie go sprawia, że uruchamia się znacznie dłużej, zanim cokolwiek będzie mogło zadziałać. Dlatego w tym poradniku skupię się wyłącznie na rozwiązaniach, jakie można osiągnąć przy wykorzystaniu wyłącznie samego środowiska. Przedstawiony zostanie opis parametrów kompilacji, sposobów ograniczania rozmiarów zasobów pliku binarnego oraz pisania krótszego kodu.
Warto sobie uświadomić, że szczególnie w przypadku kodu, krótszy wcale nie będzie musiało oznaczać szybszy. Czasem te rozwiązania idą w parze, ale często są zupełnie do siebie przeciwstawne. Dla szukających sposobu na optymalizację wydajności programu, odsyłam do porady opisującej jak tworzyć szybszy i bardziej wydajny kod w Delphi.
Nadmienię jeszcze jedną rzecz. Tych, którzy sądzą, że po przeczytaniu tego poradnika i zastosowaniu się do wskazówek w nim zawartych uda im się na utworzenie kodu o połowę mniejszego, przestrzegam, że mogą się rozczarować. Co prawda w skrajnych przypadkach jest to możliwe, ale oszczędności w większości nie będą aż tak znaczące.
Spis treści
Jak zbudowany jest plik EXE/DLL?
Wszystkie pliki EXE w systemie Windows 32/64 (a także DLL, CPL, OCX czy inne będące tylko wariacjami plików DLL, a więc plików zawierających kod binarny) składa się kilku części:
- nagłówek pliku decydujący o jego formacie i własnościach
- dane, czyli globalne zmienne, niektóre stałe
- kodu wykonywalnego
- zasobów (ang. resources)
- importy, czyli wykorzystywane funkcje w powiązaniu statycznym z innymi plikami DLL
- eksporty, czyli funkcje, jakie można wykorzystać na zewnątrz (dotyczy to plików DLL i pochodnych)
- relokacje
Oczywiście znaczną część – ponad 90% – zajmują sekcje kodu i zasobów. I to właśnie te sekcje można zoptymalizować pod względem wielkości. Powiedzieć też trzeba, że sekcje te są wyrównywane do dość dużych bloków. Dlatego często czynione zmiany wydają się w ogóle nie wpływać na wielkość pliku wynikowego. To jest faktem. Ale nie znaczy, że należy ignorować je. Może się okazać, że po takich zmianach wystarczy zaoszczędzić jeszcze jeden bajt, by nagle plik wynikowy zmniejszył się o jeden kilobajt.
Co jest w zasobach?
Zaczniemy od sekcji zasobów. Aby móc optymalizować i zmniejszać tą część pliku, należy wcześniej uważnie przyjrzeć się, co w niej umieszcza kompilator (a ściślej – linker) Delphi. Zapewne bardziej doświadczeni programiści lub osoby zajmujące się hackingiem już zdążyli poznać budowę tej interesującej części. Dla tych, którzy jeszcze nie mieli styczności, warto wspomnieć, że istnieją programy, które służą do przeglądania i edycji zasobów. Należą do nich m.in. ResHacker, WinHacker czy ExeScope.
W zasobach pliku EXE umieszczanych jest szereg danych, jak:
- dźwięki
- kursory
- bitmapy
- ikony
- okna dialogowe i formatki
- tablice tekstów
- Informacje o wersji
Generalnie zasoby zbudowane są w bardzo elastyczny sposób. Pozwala to na umieszczenie w nich zupełnie dowolnych danych; nawet innego pliku EXE! System Windows, za pośrednictwem interfejsu WinAPI, pozwala na bardzo wygodne wykorzystywanie plików umieszczonych w zasobach.
Wprawne oko szybko odnajdzie tam, w przypadku plików wygenerowanych w Delphi, bitmapy używane (bądź nie) na przyciskach klasy TBitBtn, kursory dostępne w Delphi a nie będące standardowym kursorem systemowym, pliki DFM zawierające definicje wyglądu formatek, ciągi tekstowe z komunikatami o błędach i nie tylko, a nawet dźwięki lub animacje, jakie można wykorzystać w swoim programie poprzez niektóre zewnętrzne komponenty. Co można a co nie zrobić z zasobami, o tym będzie w dalszej części.
Jak ustawić opcje kompilatora, aby generować jak najmniejsze pliki EXE?
Podstawą jest właściwe ustawienie kompilatora. Niewłaściwa konfiguracja spowoduje, że kod wykonywalny będzie dłuższy, wolniejszy, a zasoby będą obciążone niepotrzebnymi informacjami. Jak więc należy ustawić opcje, aby uzyskać jak najmniejszą ilość danych w pliku EXE? Przedstawię to na przykładzie opcji widocznych w Delphi XE2, ale wszystkie je można znaleźć już w najwcześniejszych wersjach kompilatora. W przypadku Delphi XE warto zwrócić uwagę na to, że domyślnie udostępnione są dwa schematy opcji – jeden debug a drugi release i to właśnie ten drugi musimy ustawić prawidłowo i używać go do generowania tych plików, których już nie musimy testować pod kątem poprawności kodu.
Aby ustawić opcje oczywiście schodzimy w opcje projektu. No kolejnych zakładkach lub w drzewie opcji znajdziemy te, które nas interesują. Oto, jak należy postąpić z poszczególnymi opcjami, aby uzyskać jak najmniejszy plik binarny:
- Compiling – Konfiguracja tej części związana jest z wytwarzanym kodem wynikowym.
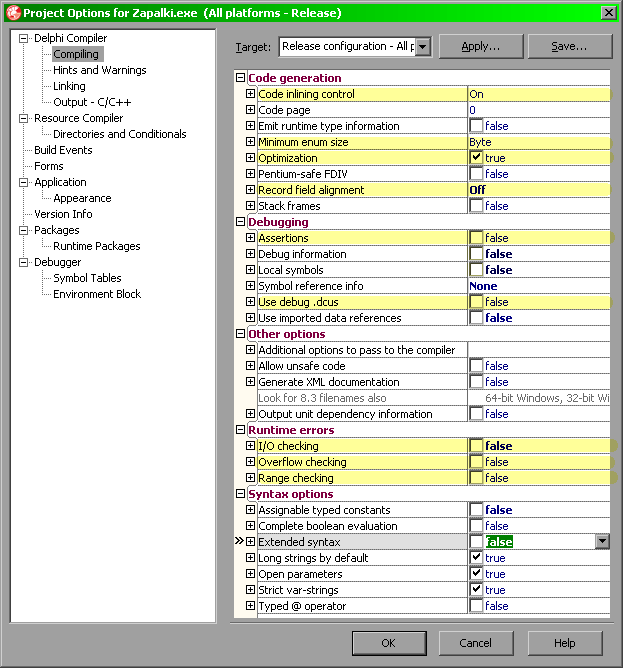
- Code Generation – Te ustawienia mają bezpośredni wpływ na sposób tworzenia kodu.
- Code inlining control – Ta funkcja pojawiła się dopiero w późniejszych wydaniach Delphi a odpowiada za zastępowanie funkcji kodem wprost w miejscu ich wywołania. Więcej na ten temat znajdzie się w części Funkcje
inline. Najlepsze ustawienie tej opcji jest na Auto co spowoduje, że wszystkie funkcje o rozmiarze mniejszym niż 32 bajty zostaną skompilowane jako inline nawet, jeśli nie zostały tak oznaczone.
- Minimum enum size – Opcja ta definiuje minimalny rozmiar dla typów wyliczeniowych. Im mniejszy, tym lepiej dla rozmiaru, a więc należy ustawić na Byte. Jednak takie ustawienie, w przypadku długich typów wyliczeniowych lub częstego wykorzystywania ich wartości w połączeniu ze zmiennymi takie ustawienie negatywnie odbije się na wydajności aplikacji.
- Optimalization – Włączenie tej opcji często spowoduje wygenerowanie mniejszego kodu, a przy okazji bardziej wydajnego. Zatem tą opcję należy ustawić na True.
- Rekord field alignment – to ustawienie przekłada się na rozmiar rekordów, a ściślej – ich wyrównanie do wielokrotności podanej wartości. Jeśli ustawimy tą opcję na False, wówczas wszystkie rekordy będą funkcjonowały jako spakowane (
packed). W przełożeniu na rozmiar wynikowego pliku ma to zastosowanie do zdefiniowanych wartości stałych. Należy jednak podkreślić, że takie ustawienie bardzo negatywnie wpłynie na wydajność aplikacji.
- Debugging – Sekcja ta związana jest z umieszczaniem w kodzie dodatkowych danych i instrukcji służących debuggowaniu.
- Assertions – Asercje odpowiadają za sprawdzanie poprawności logiki przekazanych parametrów i w przypadku wykrycia niezgodności, zgłaszają wyjątek. Wiele przykładów wykorzystania można znaleźć w module
Math, gdzie np. funkcja sprawdzenia, czy dana wartość mieści się w zadanym przedziale, po włączeniu asercji sprawdza dodatkowo, czy dolny zakres podanego przedziału jest mniejszy lub równy górnemu. Odznaczenie tej opcji przyczyni się zarówno do zmniejszenia rozmiaru kodu wynikowego, jak i poprawy jego wydajności.
- Debug information i Local symbols – Opcje te nakazują umieszczenie w pośrednim pliku wynikowym dodatkowych informacji ułatwiających debugowanie (z tablicą numeracji linii dla funkcji oraz z nazwami zmiennych umożliwiając ich edycję). Może to zaskoczyć, ale te opcje nie mają wpływu ani na rozmiar pliku wynikowego, a ni na jego wydajność! I właśnie z tego powodu postanowiłem je opisać.
- Use debug .dcus – włączenie tej opcji powoduje, że zamiast dołączania standardowej ścieżki z plikami dcu, dołączana jest ta, która w opcjach wskazana jest jako do wykorzystania w trybie debug. W pewnych przypadkach pliki tam znajdujące się mogą być obciążone dodatkowym kodem, który zwiększy i spowolni naszą aplikację. Dlatego tą opcję należy wyłączyć.
- Runtime errors
- I/O checking – Ten parametr decyduje o włączeniu do kodu części odpowiedzialnych za sprawdzanie stanu operacji wejścia-wyjścia (np. zapisu lub odczytu plików). Wyłączenie spowoduje wygenerowanie mniejszego kodu, ale niektóre funkcje wejścia-wyjścia przestaną zwracać wyjątki i konieczne będzie sprawdzanie samemu rezultatu działania poprzez superglobalną zmienną
IOResult.
- Overflow checking – Podobnie jak w poprzednim przypadku, tak i tu opcja dołącza dodatkowy kod sprawdzający przekroczenie zakresu zmiennych. Włączenie nie tylko spowoduje większy kod wynikowy, ale i bardzo spowolni działanie programu, dla tego należy tą opcję wyłączyć. Niestety, poza kodem asemblera, nie ma innej możliwości, aby samemu sprawdzić powstanie takiej sytuacji.
- Range checking – Ta własność jest bardzo podobna do poprzedniej, ale sprawdza indeksy dla tablic oraz ciągów tekstowych generując wyjątek w przypadku ich przekroczenia (zamiast np. błędu odwołania do pamięci). Podobnie jak poprzednio, wyłączenie to mniejszy i szybszy kod.
- Linking – ta część ustawień dotyczy tego, co ma wykonać linker, a więc nie ma już wpływu na kod, lecz może zmieniać zasoby pliku wynikowego.
- Debug information – włączenie opcji spowodowało by umieszczenie w pliku tablicy z numeracją linii w kodzie źródłowym bezpośrednio w pliku wykonywalnym. Dlatego należy wyłączyć.
- EXE description – jest to dość ciekawa opcja, która pozwala zaszyć w pliku krótki (do 255 znaków) jego opis. Zasadniczo te informacje do niczego nie są potrzebne, a dostęp do nich jest utrudniony. Dlatego w tym przypadku najlepiej pozostawić pusty ciąg znaków.
- Include remote debug symbols – o ile nie zostanie włączona opcja wydzielenia tych informacji do osobnego pliku, to jest to najbardziej zabójcza opcja dla wielkości pliku wynikowego i należy ją bezwzględnie wyłączyć. Symbole do zdalnego debugowania służą dla zewnętrznych debuggerów do prześledzenia i opisania powstających w aplikacji błędach.
Jak jeszcze można wpłynąć na kompilator i linker - Dyrektywy
Niestety nie wszystko da się ustawić w oknie właściwości projektu. Aby dalej ograniczać wielkość tworzonego pliku, trzeba posłużyć się poleceniami dla kompilatora zapisanymi wprost w kodzie. A jest ich kilka, które mogą przynieść łącznie nawet kilka procent oszczędności.
Pierwszym z tematów jest tablica relokacji, która zawierana jest we wszystkich plikach wykonywalnych. Wskazuje ona przesunięcia poszczególnych bloków kodów względem początku. W przypadku programów 16-bitowych jest ona niezbędna. Jednak w aplikacjach 32-bitowych wykonywanych pod kontrolą systemu Windows XP lub nowszego stała się ona zbyteczna, gdyż początek programu zawsze znajduje się na adresie startowym. Co prawda pomaga mechanizmowi randomizacji, ale... Wszak zawsze ktoś mógłby wyciąć tą tablicę. Zatem w przypadku plików EXE będących samoistnym procesem tablicy relokacji można się pozbyć.
Jak zrobić to w Delphi (od wersji 2006; we wcześniejszych prawdopodobnie nie da to rezultatu)? Wystarczy prosta dyrektywa, która zostanie odczytana przez linker, umieszczona choćby w pliku projektu (*.dpr):
{$SetPEFlags IMAGE_FILE_RELOCS_STRIPPED}
Pamiętajmy, że oznaczenie można znaleźć w pliku WinAPI.Windows (w starszych wersjach kompilatora po prostu Windows), dlatego trzeba dołączyć ten plik do sekcji uses. Alternatywnie można posłużyć się po prostu liczbą 1.
Uwaga, nie wolno tego robić w przypadku bibliotek DLL lub plików (w tym także EXE), które stają się częścią przestrzeni istniejącego procesu!
Warto zaznaczyć, że sam Microsoft nie umieszcza tabeli relokacji w swoich plikach wykonywalnych, a wiele kompilatorów (linkerów) samoczynnie usuwa tablicę relokacji. Często robią to także programy pakujące pliki wykonywalne (jak UPX).
Drugą rzeczą jest RTTI (Run Time Type Information), który m.in. udostępnia informacje o używanych w pliku klasach na zewnątrz. RTTI w nowej formie i publikacja danych zostały pierwszy raz wprowadzone do Delphi 2010; w starszych wersjach także istniało RTTI, ale działało na zupełnie innych zasadach, a informacji tych nie można się pozbyć. Informacje nowego RTTI są wykorzystywane często przez debuggery, testery (np. DUnit) a także ma zastosowanie do refleksji (ang. Reflection) w platformie .NET. Jednakże zapewne w większości przypadków takich informacji w ogóle nie potrzebujemy, nie są też potrzebne do działania programu (o ile jawnie nie korzysta z udogodnień RTTI), a wręcz ich ujawnianie może być nie na rękę.
Pozbywając się tych informacji możemy zaoszczędzić tym więcej miejsca, im więcej klas z publicznymi polami i metodami używamy w kodzie. Jak to zrobić? Znów trzeba posłużyć się dwiema dyrektywami kompilatora:
{$WEAKLINKRTTI ON}
{$RTTI EXPLICIT METHODS([]) PROPERTIES([]) FIELDS([])}
Oba powyższe zapisy pozwolą usunąć wszystkie informacje RTTI.
Zaznaczyć należy, że w przypadku starszych wersji Delphi wystarczyło taki zapis umieścić raz w dowolnym pliku. W nowszych wersjach (od XE5) ta dyrektywa musi być umieszczona na początku (pod definicją unit) każde z plików, w którym występują klasy.
Warto jednak mieć na uwadze, że RTTI staje się coraz popularniejsze i chętnie wykorzystywane. Poza przytoczonym przykładem DUnit informacje są używane także np. przez moduły obsługi obiektów JSON (zamiana w czasie rzeczywistym całych obiektów na ciągi JSON i odwrotnie), wykorzystują też niektóre elementy DataSnap. Z podobnego też powodu nie należy próbować wyłączać tego dla modułów standardowych, czyli np. RTL i VCL.
Używanie tylko niezbędnych unitów
W sekcji uses naszych plików pas lub dpr znajdują się wszystkie moduły, jakie są brane pod uwagę w procesie kompilacji. Zawierają one wykorzystywane funkcje, stałe, struktury i wiele innych elementów. Domyślnie, przy tworzeniu nowej aplikacji, Delphi samodzielnie tworzy niemałą listę sekcji uses. Tymczasem części z nich w ogóle nie wykorzystamy, a zawarte tak dane mogą powiększać zarówno część danych jak zasobów naszego pliku wynikowego. Dla plików DLL są to SysUtils i Classes, które wcale nie są niezbędne, a ich zawarcie zwiększa plik wynikowy o kilkadziesiąt do kilkuset kilobajtów (w zależności od wersji Delphi). Znacznie więcej dostajemy w przypadku nowej aplikacji. Tam lista jest znacznie dłuższa.
Jak więc usuwać niepotrzebne moduły? Sprawa jest dość skomplikowana. Delphi niestety nie dysponuje narzędziem analizy wykorzystania i automatycznego usuwania nieużywanych modułów. A nieoptymalny kompilator dorzuca do pliku dane niezależnie od tego, czy są wykorzystywane czy nie (np. ciągi zasobów, grafiki itp.). Pozostaje wykorzystanie jednej z metod:
- Bardzo duże doświadczenie i wiedza na temat tego, co znajduje się w poszczególnych modułach,
- Dobre radzenie sobie z pomocą,
- Metoda prób i błędów – najbardziej skuteczna, ale i czasochłonna. Polega na tym, że wyrzucamy wszystkie moduły, a następnie dodajemy te, które są potrzebne dla zastosowanej funkcji, przy której kompilator zgłosił błąd nierozpoznania.
Należy jednak nadmienić, że często jedne moduły zawierają inne. Dlatego nawet jak wyrzucimy przykładowo moduł Graphics z naszego projektu, to nic to nie zmieni, gdyż moduł StdCtrls i tak go zawiera. Niemniej także informacje o wykorzystywanych paczkach (packages) części interfejsowej są zawarte w zasobach, dlatego mimo wszystko nie należy rezygnować z usuwania niepotrzebnych, a dodatkowo należy zadbać o przeniesienie do części implementacyjnej tak dużo, jak tylko jest to możliwe. Dobrym przykładem są takie unity, jak Registry, IniFiles, Math czy ShellAPI, których obecność w części interfejsowej w 99% przypadków jest zupełnie zbyteczna.
Oczywiście możliwe jest nieużywanie żadnych modułów. Ale wówczas wszystkie potrzebne funkcje będziemy musieli sami linkować z interfejsu WinAPI lub definiować pewnie niezbędne funkcje, które nie posiadają odzwierciedlenia w kodzie. A jeśli ktoś używa Delphi, to raczej nie po to, aby ręcznie w kodzie rzeźbić formatki (choć jest to możliwe i potrafi diametralnie zmniejszyć rozmiar pliku wynikowego nawet do kilkudziesięciu kilobajtów dla prostych pojedynczych formatek!).
W pewnych sytuacjach takie postępowanie jest jednak wskazane! Przykładowo bardzo często wykorzystywana jest funkcja ShellExecute, która znajduje się w module ShellAPI. Jeśli jest to jedyna funkcja wykorzystywana z tego modułu, to z pewnością nie ma najmniejszego sensu dołączać jej! Co więc zrobić? Wystarczy zajrzeć do modułu ShellAPI i poszukać tej funkcji... Znajdziemy dwie jej definicje:
function ShellExecute; external shell32 name 'ShellExecuteW';
oraz
function ShellExecute(hWnd: HWND; Operation, FileName, Parameters,
Directory: PWideChar; ShowCmd: Integer): HINST; stdcall;
(zapis powyżej jest domyślnym dla Delphi obsługującego natywnie standard Unicode, a więc w wersji od 2010 wzwyż.
Dodatkowo znajdujemy, że shell32 to nic innego, jak stała wskazująca nazwę pliku shell32.dll. Wystarczy więc w swoim programie umieścić następujący kod:
function ShellExecute(hWnd: HWND; Operation, FileName, Parameters,
Directory: PWideChar; ShowCmd: Integer): HINST; stdcall; external 'shell32.dll' name 'ShellExecuteW';
lub w przypadku starszych wersji Delphi:
function ShellExecute(hWnd: HWND; Operation, FileName, Parameters,
Directory: PChar; ShowCmd: Integer): HINST; stdcall; external 'shell32.dll' name 'ShellExecuteA';
W ten sposób bez dołączania całego modułu ShellAPI w sekcji uses mamy możliwość skorzystania z funkcji ShellExecute oszczędzając przy tym sporo na rozmiarze pliku wynikowego!
Oczywiście w analogiczny sposób możemy postępować z wszelkimi innymi funkcjami ze wszystkich modułów. Jeśli są to elementy interfejsu WinAPI, to zapis będzie wyglądał jak powyżej. Jeśli będą to funkcje środowiska, to będzie trzeba przekopiować je w całości. Oczywiście są przypadki, gdzie zależności są tak złożone, że trzeba by powielić sporą część modułu - wtedy zabawa traci sens. Lecz dla pojedynczych funkcji takie działanie jest jak najbardziej wskazane!
Jak projektować formatki, aby zmniejszyć rozmiar zasobów?
 A skoro już przy projektowaniu formatek jesteśmy... Jak wcześniej pokazałem, w zasobach plików mamy niestety pełne, tekstowe definicje formatek. To właśnie na ich podstawie program generuje formatki i nadaje im oraz komponentom właściwe ustawienia. Co więc można zrobić, aby te informacje były jak najkrótsze? A skoro już przy projektowaniu formatek jesteśmy... Jak wcześniej pokazałem, w zasobach plików mamy niestety pełne, tekstowe definicje formatek. To właśnie na ich podstawie program generuje formatki i nadaje im oraz komponentom właściwe ustawienia. Co więc można zrobić, aby te informacje były jak najkrótsze?
Pierwszą metodą jest korzystanie maksymalnie jak tylko jest to możliwe z parametrów domyślnych. Przykładowo, jeśli na panelu kładziemy 3 komponenty typu TLabel, i każdy z nich jest zapisany czerwoną czcionką (identyczną dla wszystkich trzech) to błędem jest definiowanie tej czcionki dla każdego z nich z osobna. Należy czcionkę określić dla komponentu TPanel, a następnie na znajdujących się na nim etykietach ustawić własność ParentFont na True. Oczywiście sprawa komplikuje się nieco bardziej, jeśli znajdują się na nim także inne etykiety z innymi czcionkami. Wówczas należy tak dobrać właściwości, aby jak najmniej komponentów nie dziedziczyło ustawień czcionki po rodzicu. A może w pewnych przypadkach wprowadzenie dodatkowego panelu pomoże? Nie ma jednoznacznej odpowiedzi – wszystko zależy od ilości komponentów oraz ustawień.
Warto zwrócić uwagę, aby możliwie jak najczęściej ustawiać wszystkie własności zaczynające się od Parent... na False (p. ramka na rysunku obok). Każde takie ustawienie skutkuje znacznym wzrostem pliku wynikowego. Podobnie sprawa ma się względem wszystkich właściwości, które są niedomyślne, czyli oznaczone na oknie inspektora obiektów pogrubioną czcionką (od Delphi 7 wzwyż). Bierze się to stąd, że domyślne właściwości nie są zapisywane do pliku DFM, a więc i nie powiększają pliku wynikowego (p. rysunek obok i zaznaczone strzałki idące od pogrubionych własności). Oczywiście nie należy popadać w paranoję i pozbawiać swojej aplikacji zamierzonego wyglądu. Ale należy rozsądnie zarządzać ustawieniami.
Poza parametrami typu prawda-fałsz lub wartościami liczbowymi, występują jeszcze własności tekstowe. W ich przypadku należy zwrócić szczególną uwagę, gdyż potrafią zajmować najwięcej miejsca (w skrajnych przypadkach jeden niestandardowy znak może zająć aż 5 bajtów!). Dlatego nie pozostawiajmy żadnego tekstu np. na etykietach, których tekst i tak jest nadpisywany kodem w trakcie wykonywania programu. To zaoszczędzi nie tylko rozmiar, ale pozytywnie wpłynie też na czas ładowania formatki. Podobnie jest np. w przypadku, gdy dwie etykiety zawierają ten sam dłuższy tekst. Zamiast definiować go na formatce dla obu, należy zdefiniować tylko go wyłącznie dla jednej etykiety, a następnie w kodzie zapisać proste przypisanie w zdarzeniu OnCreate formy:
Label2.Caption := Label1.Caption
Taki kod zajmie zaledwie 28 bajtów. Tak więc dla tekstów dłuższych, niż 28 znaków (a w pewnych sytuacjach i krótszych) zdecydowanie warto zastąpić definiowanie tekstu w etapie projektowanie takim właśnie kodem.
Wiedząc, jak wygląda plik DFM i wiedząc, iż jest on częścią pliku wynikowego, można znaleźć jeszcze jeden sposób na oszczędności. Mianowicie plik wynikowy zawiera nazwy komponentów. Należy zatem starać się o maksymalne skrócenie tych nazw.
Inną metodą jest także wykorzystanie mechanizmu dziedziczenia formatek, co zostało szerzej opisane w dalszej części poradnika.
Jednak najwięcej na rozmiarze DFM można zaoszczędzić... dynamicznie tworząc kontrolki. Oczywiście takie postępowanie znacznie utrudnia projektowanie interfejsu i zbliża swą niewygodą do pisania w czystym WinAPI. Jednak np. robiąc jakąś grę w karty kategorycznie nie powinno się wstawiać na formatkę 52 obiektów, lecz wykonać to dynamicznie w kodzie aplikacji. Ustawienie prostej właściwości może pochłonąć raptem kilka bajtów, podczas gdy w pliku DFM może to zająć aż kilkanaście lub kilkadziesiąt.
Grafika na formatkach
Chyba najbardziej pochłaniającą miejsce w zasobach DFM jest grafika. Zajmuje ona ponad dwa razy więcej miejsca, niż plik graficzny, jaki został wykorzystany i osadzony na formatce. Jak więc optymalizować ilość miejsca zajmowaną przez nią?
Po pierwsze, w najnowszych wersjach Delphi mamy już wbudowane wsparcie dla grafik w formatach GIF i PNG, które to są formatami kompresji bezstratnej. Starsze wersje wspierały wyłącznie format JPEG. Zatem gdzie tylko to możliwe, należy używać właśnie tych formatów.
Jeśli jednak nie ma innej możliwości, niż użycie pliku BMP, to należy zadbać o to, aby był on zapisany w możliwie najmniejszej liczbie kolorów. Użycie bitmapy 256-kolorowej da zdecydowaną oszczędność, względem bitmapy 24-bitowej, która jest 3 razy większa.
Ale to nie koniec możliwości. Bardzo często w programach np. na przyciskach lub innych elementach używamy tych samych obrazów. I tu niestety będzie trzeba pogodzić się z uciążliwością projektowania, gdyż musimy je wyciąć i umieścić najlepiej w komponencie TImageList. W ten sposób wszystkie wystąpienia grafiki zostaną zastąpione wyłącznie jedną ich instancją. Następnie w procedurze zdarzenia tworzenia formy trzeba ręcznie przypisać te grafiki właściwym komponentom, ot choćby w ten sposób:
ImageList1.GetBitmap(0, BitBtn1.Glyph);
ImageList1.GetBitmap(0, BitBtn2.Glyph);
Choć takie działanie nieznacznie wydłuży czas tworzenia formatki, to jednak oszczędności na wielkości pliku wynikowego są nie do przecenienia.
Jeśli wykorzystujemy takie listy grafik na wielu formatkach, to gorąco polecam dodanie do projektu Data Module (jako nowy element projektu - jest to zasobnik na komponenty niewizualne, zapewne dobrze znany tym, którzy pracowali z projektami DataSnap), który moduł będzie utworzony na początku raz, a każda z formatek, w której sekcji uses znajdzie się nazwa tego modułu będzie mogła korzystać bezproblemowo z komponentów takich jak TImageList i to nawet już na etapie projektowania.
Jest i inna metoda, trochę bardziej uciążliwa, ale dająca jeszcze lepsze rezultaty. Mianowicie nigdzie w trybie projektowania grafika nie może wystąpić, lecz umieszczamy ją w zasobach. W Delphi XE2 mamy wygodny edytor zasobów; w starszych wersjach kompilatora niestety trzeba się w tym celu posłużyć zewnętrznym programem, który wygeneruje nam plik res z zasobami, które należy włączyć do programy dyrektywą kompilatora $R umieszczoną w kodzie. Tam pliki graficzne mają dokładnie ten rozmiar, jaki zajmuje plik. Gdy już nasz skompilowany program w swoich zasobach zawiera grafikę, to aby ją wykorzystać, trzeba użyć funkcji LoadBitmap z WinAPI. Niestety to rozwiązanie ma też dwie wady. Po pierwsze wczytanie grafiki z zasobów trwa znacznie dłużej. Po drugie – znacznie ułatwia podmianę grafiki w programie przez niepowołane osoby.
Ikony programów
Skoro już jesteśmy przy temacie grafiki, warto zwrócić uwagę na to, jaką ikonę dołączamy do naszego programu. Oczywiście im większy plik ikony, tym większy plik wynikowy. Dlatego warto zastanowić się, czy:
- Na pewno potrzebujemy takich rozmiarów ikony? Często nie warto umieszczać tam rozmiarów 128x128 lub większych, jeśli zależy nam na wielkości programu, gdyż mało kiedy są one wykorzystywane.
- Czy na pewno potrzeba ikon w danej palecie barw? Jeśli wykorzystujemy przeźroczystości – nie ma wyjścia. Ale jeśli nie, to z pewnością nie warto wykorzystywać tak zwanej palety XP i być może wystarczy paleta 256-kolorowa indeksowana. Z drugiej strony w dzisiejszych czasach chyba nie warto także umieszczać ikon czarnobiałych, czy w paletach 16-kolorowych (o ile ikona faktycznie nie wykorzystuje takiej małej przestrzeni i nie używamy większej)
Rozsądne przygotowanie ikony w programie do tego przeznaczonym może nam zaoszczędzić nawet kilkadziesiąt kilobajtów miejsca.
Optymalizacja miejsca dla ciągów tekstowych oraz stałe zasobowe resourcestring
W poprzedniej części zwróciłem uwagę na ogrom miejsca zajmowany przez ciągi tekstowe. Nie inaczej jest w samym kodzie programu. Jak Delphi radzi sobie z ciągami tekstowymi podczas kompilacji?
O dziwo, najnowsze wersje kompilatora traktują stałe (bądź to wyrażone w sekcji const), bądź zapisane wprost w kodzie jako faktycznie składowane w części danych i wszelkie odwołania w kodzie powodują odwołanie do jednego miejsca. Inaczej odbywało się w najstarszych wersjach kompilatora, gdzie wcześniej wszystkie stałe były podstawiane w miejscu ich wystąpienia i dopiero kompilowane, co powodowało powielanie ciągów w kodzie. To sprawia, że w najnowszych wersjach kompilatora ten element został już zoptymalizowany pod względem ilości miejsca, choć w przypadku złączeń takie działanie zaowocuje spadkiem wydajności aplikacji.
W przypadku starszych kompilatorów zmuszenie do takiej właśnie kompilacji można było osiągnąć wyłącznie w jeden sposób – poprzez użycie ciągów tekstowych umieszczanych w zasobach. Stałe takie deklaruje się w sekcji resourcestring, a deklaracja może wystąpić w dowolnym miejscu poza kodem. Jednak takie działanie przynosiło efekt tylko w przypadku dłuższych ciągów, gdyż odwołanie się do zasobu wymagało przeszło 20 bajtów w kodzie. Ponadto pobieranie tekstu z zasobów jest operacją bardzo powolną w porównaniu ze stałymi.
Kolejnym elementem zmniejszającym ilość miejsca zajmowanych przez ciągi jest zastępowanie powtarzających się sekwencji znaków specjalną funkcją StringOfChar. Z pewnością nieraz w programie zapisywało się bądź to ciąg kresek, kropek lub spacji dla wprowadzenia wyrównania lub specyficznego efektu. Tego typu dłuższe ciągi z powodzeniem można zastąpić właśnie przytoczoną funkcją podając tylko jeden znak oraz liczbę powtórzeń. Jeśli takich ciągów jest więcej, to w miarę możliwości należy wynik działania funkcji umieścić w zmiennej i wykorzystać później już tylko tą zmienną.
Warto też zwrócić uwagę na bardzo często powtarzany przez programistów błąd zapisu formatu dla liczb. Często, chcąc wprowadzić do swojej liczby, zamienianej na tekst, separator tysięcy, stosują polecenie np.: FormatFloat('# ### ### ##0.00', liczba). Tymczasem zapis taki jest niepotrzebnie nadmiarowy. Wystarczy skrócenie ciągu do następującej postaci: FormatFloat(',0.00', liczba). Co więcej, taki zapis zastosuje domyślny systemowy separator tysięczny (częściej właśnie tak powinno się postępować, niż wymuszać użytkownikowi spację, która może być niechciana w pewnych sytuacjach).
Funkcje i funkcje inline
Zajmiemy się teraz zmniejszeniem rozmiaru samego kodu wykonywalnego. Najprostszą techniką jest wykorzystanie funkcji dla zastąpienia powtarzalnych logicznych części kodu. Możliwości jest tak wiele, że trudno opisać konkretny przykład zastosowania. Ale posługując się wręcz podręcznikowym przykładem: załóżmy, że mamy program wyliczający pola powierzchni i objętości figur geometrycznych. Jak wiadomo, do obliczeń związanych ze stożkami czy walcami potrzebujemy znać pole powierzchni koła. Co więcej, musimy sprawdzić poprawność danych. A przy okazji można policzyć pole wycinka koła. I właśnie wyliczenie tej wartości powinno znajdować się w funkcji, np. takiej:
function PoleWycinkaKola(const r: Real; const a: Real = 360): Real;
const
Err_r = 'Podana wartośc promienia ''%f'' nie jest poprawną! Wartość musi być dodatna.';
Err_a = 'Podana wartośc kąta wycinka koła ''%f'' nie jest poprawną! Wartość musi być się w przedziale 0-360°';
begin
if r < 0 then
raise Exception.Create(Format(Err_r, [r]));
if not Math.EnsureRange(a, 0, 360) then
raise Exception.Create(Format(Err_a, [a]));
Result := 3.1415 * r * r * (a / 360);
end;
Dzięki temu kod będzie mniejszy, choć będzie wykonywał się dłużej (każde wywołanie funkcji i powrót z niej obciążone jest szeregiem czasochłonnych instrukcji).
No właśnie, warto na chwilę zatrzymać się nad uwagą podaną w nawiasie. Każde wywołanie funkcji to dodatkowe instrukcje, które wydłużają kod. Stąd zastępowanie funkcją np. wyniku sumy trzech liczb zamiast spodziewanego spadku ilości miejsca zajmowanego przez kod, przyniesie zupełnie odwrotny skutek i kod wynikowy zwiększy się! Wróćmy na chwilę do punktu opisującego opcje kompilatora. Podczas opisu opcji Code inlining control zaleciłem używanie opcji auto. Takie ustawienie zapewni nam, że małe funkcje wcale funkcjami się nie staną i zostaną zastąpione ekwiwalentem ich zawartości w miejscu wywołania. Dzięki temu kompilator sam dba o rozmiar pliku wynikowego. Gdyby ta opcja była w stanie on, wówczas sami musielibyśmy przy nagłówku takich krótkich funkcji wpisać modyfikator inline.
A co, jeśli używamy starego kompilatora, który nie obsługuje dyrektywy inline? Cóż, wówczas pozostaje nam jedynie samemu zastąpić wywołania takich funkcji ich zawartością w kodzie. Kiedy to zrobić? To już trudniejsze pytanie. Ale im mniej instrukcji, tym bardziej jest to wskazane. W większości przypadków funkcje zawierające do 5 prostych linii kodu nie przynoszą oszczędności miejsca. (Zwróćmy uwagę, że w przedstawionym przykładzie są dwa porównania, pięć wywołań innej funkcji oraz cztery operacje matematyczne.)
Dziedziczenie i ramki
Często dobrą metodą do zaoszczędzenia kodu, jest umiejętne wykorzystywanie mechanizmu dziedziczenia. Przy czym nie ogranicza się to wyłącznie do prostych klas. Dziedziczącymi mogą być całe okna naszego programu! Załóżmy, że mamy w programie 10 okien, z których każde przy wyjściu zapisuje swoje położenie w rejestrze, a przy tworzeniu czyta te położenie z rejestru. Dodatkowo wszystkie te okna wyposażone są w przyciski OK i Anuluj. Zamiast tworzyć w każdej z klasie okna te same funkcje, znacznie lepiej będzie utworzyć jedno okno bazowe, a następnie 10 okien dziedziczących po nim.
Jak to zrobić? Tworzymy okno bazowe, tworzymy funkcje, które będziemy zawsze wywoływać oraz umieszczamy komponenty, które wystąpią wszędzie na naszych oknach. Następnie zapisujemy. Teraz tworząc nowe okno dziedziczące, zamiast wybrać opcję New / Form wybieramy New / Other... i wskazujemy sekcję dziedziczenia Inheritable items wybierając nasze okno bazowe. Każde okno stworzone może stać się oknem bazowym dla innego.
W ten sposób nie tylko wyłącznie w jednym miejscu w całym kodzie zapisaliśmy treść powtarzających się funkcji. Ponadto wyłącznie w jednym miejscu w zasobach znajdą się definicje dwóch przycisków oraz specyficznych ustawień formy. Wszystkie okna dziedziczące w plikach DFM będą miały wyłącznie te zapisy, które nie występują na oknie bazowym. Przy okazji zmieniliśmy stany domyślne dla osadzonych komponentów!
Podobnym mechanizmem do dziedziczenia są rzadko wykorzystywane ramki (frame). Są to specjalne klasy, które pomagają w prosty sposób agregować kilka komponentów wraz z towarzyszącymi im funkcjami obsługi zdarzeń. Ponadto możemy także stworzyć własne funkcje dla ramki. Przykładowo, chcemy stworzyć coś na kształt komponentu TButtonedEdit (jest to komponent wprowadzony w nowszych wersjach kompilatora; jest to połączenie pola edycyjnego i przycisku), lecz przycisk ma mieć specjalną ikonę, a jego kliknięcie powinno otwierać okno dialogowe otwarcia pliku i umieszczać w polu edycyjnym nazwę wskazanego pliku. Dodatkowo takie zestawienie używamy w kilku miejscach w programie. Jest to sytuacja wręcz stworzona do wykorzystania właśnie ramki z trzema komponentami. W ten sposób zamiast mnożyć liczbę komponentów (i powiększać plik DFM), powielamy wyłącznie samą ramkę. Dodatkowo kod, który odpowiada za wpisanie nazwy pliku do pola edycyjnego znajduje się wyłącznie w jednym miejscu w całym kodzie programu.
Aby stworzyć ramkę postępujemy podobnie jak poprzednio, lecz tym razem z sekcji Delphi files wybieramy VCL Frame
Następnie taką ramkę możemy umieścić na formie wybierając z palety komponentów, z zakładki Standard pierwszy element o nazwie Frazes. Po wybraniu i wskazaniu miejsca na formie, wyświetlone zostanie okno z listą wszystkich ramek, jakie są dołączone do projektu. Wystarczy wskazać właściwą.
Pozbywanie się zbędnego kodu
W przypadku, gdy mamy do czynienia z nieużywanymi metodami prywatnymi klas, lub nieużywanymi funkcjami czy zmiennymi, kompilator bez specjalnego pozwolenia nie umieści ich w pliku wynikowym dbając o jego rozmiar. Jednak kompilator nie poprawi oczywistych błędów kodu. Załóżmy, że chcemy skrótem klawiszowym włączać i wyłączać na przemian widoczność jakiegoś panelu. Tworzymy więc akcję, przypisujemy skrót klawiaturowy i definiujemy funkcję:
if pnlSzukaj.Visible then
pnlSzukaj.Hide
else
pnlSzukaj.Show;
Otóż błąd! Jest to często popełniana przez początkujących programistów pomyłka. Mamy tutaj dużo kodu, który można zastąpić jednym krótkim:pnlSzukaj.Visible := not pnlSzukaj.Visible;
Oczywiście jest to prosty przykład pozbywania się nadmiarowego kodu. Innym przykładem jest nadużywanie instrukcji if..else dla sprawdzenia stanu jednej zmiennej:
if AnsiUpperCase(Edit1.Text) = 'T' then Result := 1
else if AnsiUpperCase(Edit1.Text) = 'N' then Result := -1
else Result := 0;
Taki ciąg instrukcji często większy objętościowo, a z pewnością przy okazji dużo wolniejszy powinno zastąpić się poleceniem case:
Result := 0;
if Length(Edit1.Text) <> 1 then
Exit;
case AnsiUpperCase(Edit1.Text)[1] of
'T': Result := 1
'N': Result := -1;
end;
Jeśli zaś istnieje potrzeba porównania dłuższych ciągów, warto rozważyć użycie funckji AnsiIndexText (lub AnsiIndexStr jeśli chcemy rozróżniać wielkość znaków) w połączeniu z instrukcją case.
Kolejnym częstym negatywnym przykładem jest niewykorzystywanie tych samych zmiennych lub nawet obiektów. Ten drugi przypadek często spotyka się w aplikacjach bazodanowych, gdzie każde jedno zapytanie ma utworzony i zwalniany obiekt.
with TFDQuery.Create(nil) do
begin
try
Connection := MyDB;
SQL.Text := 'SELECT nazwa FROM tabela WHERE id_klucz = 5';
Open;
Nazwa := FieldByName('nazwa').AsString;
Close;
finally
Free;
end;
end;
with TFDQuery.Create(nil) do
begin
try
Connecion := MyDB;
SQL.Text := 'INSERT INTO tabela2 (nazwa) VALUES(:nazwa)';
ParamByName('nazwa').AsString := Nazwa;
ExecSQL;
finally
Free;
end;
end;
Po co za każdym razem zwalniać I na nowo rezerwować obiekt? Jest to rozwiązanie zarówno czasochłonne, jak i zajmuje więcej miejsca w kodzie. Takie sekwencje bez zastanowienia powinny być zastąpione następującą:
with TFDQuery.Create(nil) do
begin
try
Connection := MyDB;
SQL.Text := 'SELECT nazwa FROM tabela WHERE id_klucz = 5';
Open;
Nazwa := FieldByName('nazwa').AsString;
Close;
SQL.Text := 'INSERT INTO tabela2 (nazwa) VALUES(:nazwa)';
ParamByName('nazwa').AsString := Nazwa;
ExecSQL;
finally
Free;
end;
end;
Jeszcze innym przykładem jest niewykorzystywanie rozwiązań, jakie oferują nam komponenty. Początkujący programiści, którzy nie wiedzą do czego służy własność Anchors często zamiast wykorzystać jej zalety piszą niepotrzebnie kod w procedurze obsługi zdarzenia OnResize dla formy. Zupełnie niepotrzebnie. Dlatego proponuję zapoznać się dogłębnie ze wszystkimi możliwościami i funkcjami, jakie dostarcza nam środowisko Delphi.
Można mnożyć inne przykłady, ale w tym miejscu odeślę do poradnika o tworzeniu wysokowydajnego kodu, gdyż w przypadku nadmiarowego kodu wielkość i szybkość działania idą w parze. Pragnę zwrócić uwagę, że nie wszystkie porady tam zawarte wpłyną pozytywnie na wielkość binarki, ale myślę, że bardziej wprawieni bez trudu wychwycą właśnie takie porady, które przynoszą korzyści na obu polach.
Czy można jeszcze więcej
Ci, którzy pracowali z kolejnymi wersjami środowiska Delphi, z pewnością zauważyli, że każda kolejna wersja produkuje coraz większe pliki wykonywalne. Największe skoki były przy przejściach z wersji Delphi 2 na Delphi 3 (spora rewolucja w generowanych kodach), Delphi 7 na Delphi 8, następny skok w środowisku Delphi 2009 (wprowadzenie Unicode) i 2010 (Nowy RTTI, który związał się ze standardowymi elementami RTL i VCL). Niestety ten trend się nie zatrzymuje. Choć kod jest coraz prostszy do pisania, to jednak - zdaje się nie najlepiej dopracowany - optymalizator dokłada coraz to nowe zupełnie niepotrzebne nam elementy.
Czy coś można poradzić poza powrotem do starszych wersji, które ani nie wspierają Unicode ani nie pozwolą w prosty sposób na tworzenie aplikacji zgodnych z Windows 10 i jego rozwiązaniami? Po części tak. Sama rezygnacja z VCL pozwoli na duże oszczędności. Jednak pisanie całej aplikacji z wykorzystaniem WinAPI - choć możliwe - spowoduje potworny przyrost ilości kodu, którym musi się zaopiekować programista. Można uciec się też do alternatywy w postaci KOL (niestety, na podanej stronie wsparcie skończyło się nawersji Delphi XE). Można również korzystać z pakerów aplikacji wykonywalnych, jak UPX, choć jest to raczej drobne oszustwo niż faktyczne redukowanie rozmiaru pliku.
Z drugiej jednak strony kompilator nie stoi w miejscu i najnowsze wersje potrafią stworzyć mniej obszerny (a co za tym idzie - szybszy!) kod wynikowy z tego samego kodu źródłowego. Choć oczywiście oszczędności w wielkości ostate4cznej pliku są szybko zjadane przez inne elementy, to jednak wydajność wykonywania bezapelacyjnie zyskuje. |






