Optymalny, wysokowydajny kod w DelphiBazując na własnych wieloletnich doświadczeniach pragnę przedstawić przykładów, jak w prosty sposób dokonać optymalizacji wydajnościowej aplikacji w Delphi. Skupię się tutaj na tym, w jaki sposób kompilator Delphi tłumaczy kod źródłowy na język maszynowy (przy wykorzystaniu zapisu Assemblera), a także przedstawię kilka szczegółów dotyczących wykonywania poleceń przez procesor. Artykuł adresowany jest w głównej mierze do bardziej zaawansowanych programistów oraz mających jakieś pojęcie o języku Assembler. Jednakże pewne przedstawione schematy mogą być wykorzystane także przez początkujących, którym także zależy na tym, aby aplikacja działała możliwie jak najszybciej. Wszystkie przedstawione porady będą bazować na prostych modyfikacjach pewnych podstawowych czynności. Nie chcę przedstawiać tutaj żadnych algorytmów, których właściwy dobór często może dać znacznie lepsze rezultaty, o czym nie należy zapominać. Przykłady opierać się będą na kompilatorze Delphi 10. Jest to o tyle istotne, że inne wersje kompilatora mogą dokonywać innych tłumaczeń na kod procesora, przez co wyniki w pewnych przypadkach mogą się różnić w zależności od kompilatora.
Spis treści
Z czego będziemy korzystać
W przeważającej mierze skupię się na tym, jak kod wygląda na procesorze. Głównym celem będzie zmniejszenie ilości instrukcji wykonywanych przez procesor; w mniejszym stopniu skupię się na czasie wykonywania poszczególnych instrukcji (niektóre potrzebują większej liczby taktów procesora, inne mniej). Z tych to powodów do wykonywania testów potrzebne są dwie rzeczy w środowisku Delphi. Pierwszą jest włączenie opcji w oknie właściwości projektu, które pozwolą dołączyć do projektu informacje potrzebne do debuggowania programu:
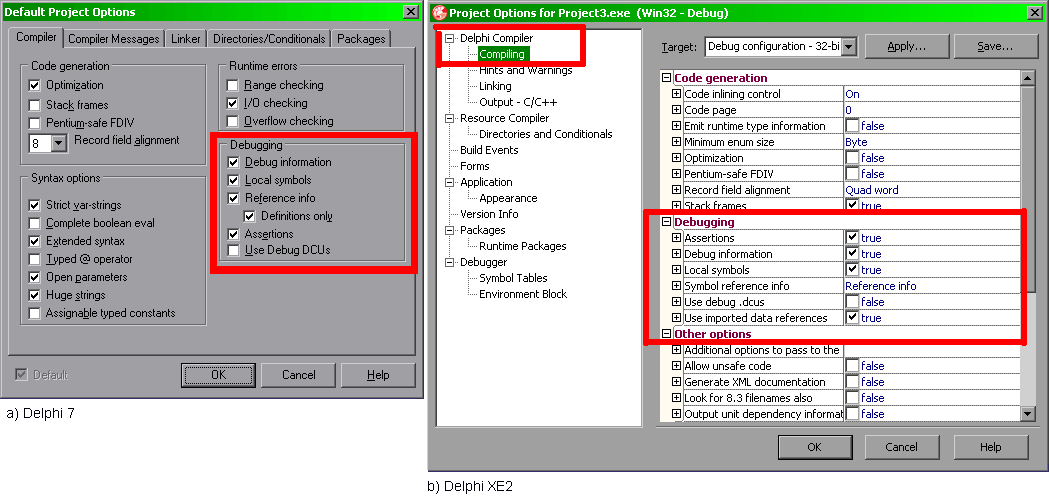
Oczywiście, jeśli naszą aplikację chcemy udostępnić innym, to przed publikacją należy wszystkie zaznaczone opcje wyłączyć (tzw. kompilacja release).
Drugą rzeczą jest okno debuggera na poziomie procesora. Wywołać je można poprzez opcję wskazaną na rysunku poniżej i tylko wówczas, gdy ustawimy aplikacja jest uruchomiona, a więc najlepiej, gdy ustawiony jest breakpoint na początku optymalizowanego fragmentu kodu.
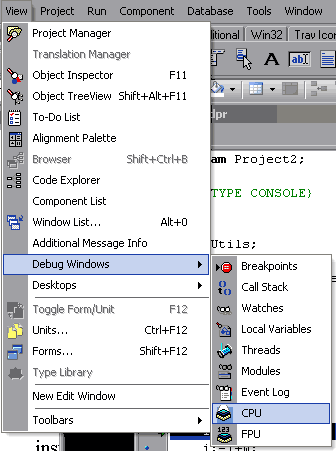
Opisywane okno składa się z kilku części; dla nas najważniejsza będzie główna część – kodu procesora. Na prawo od niej widnieją jeszcze podgląd zawartości rejestrów pamięciowych oraz rejestrów flagowych procesora.
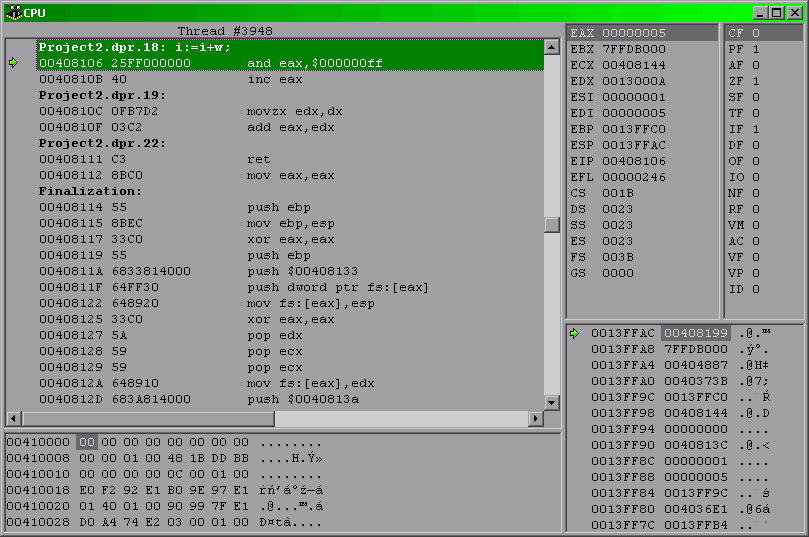
Przechodzenie do kolejnych linii kodu odbywa się identycznie, jak w oknie kodu źródłowego – klawiszem F8. Różnica jest taka, że następuje przejście do kolejnych poleceń procesora, a nie linii kodu; każda linia kodu (zaznaczona w tym oknie czcionką pogrubioną; gdyby tak nie było wystarczy posłużyć się skrótem Ctrl+X) może składać się nawet z kilkudziesięciu poleceń procesora.
Bardzo wygodnym rozwiązaniem w badaniu wydajności kodu jest instrukcja GetTickCount pochodząca z WinAPI, która zwraca liczbę milisekund od momentu uruchomienia systemu Windows. Wystarczy więc przed badanym fragmentem kodu zapamiętać zwracaną wartość, a następnie sprawdzić różnicę.
var
c: LongWord;
begin
c := GetTickCount;
//Badany fragment, opcjonalnie puszczony w pętli powtarzającej wywołanie funkcji Test
Writeln(Format(‘Badany fragment kodu wykonywał się %d ms‘, [GetTickCount - c]));
end;
Należy pamiętać, iż badając wydajność często nie wystarczy pojedyncze wykonanie danego algorytmu, lecz koniecznie jest jego wielokrotne powtórzenie. Zapewni to nie tylko, że wyniki będą bardziej mierzalne, ale także uśredni błędy związane z faktem, iż pracujemy w środowisku wielozadaniowym, stąd za każdym razem czas wywołania tego samego kodu będzie różny.
Co daje optymalizacja?
Optymalizacja szczególnie w starszych kompilatorach była często zapominana, a jest to niezwykle istotna opcja, jeśli zależy nam, aby kompilator generował szybszy kod. Można włączyć ją albo poprzez dyrektywę kompilatora {$O+}, albo poprzez zaznaczenie odpowiedniej opcji w oknie właściwości projektu (p. rysunek 1, lewy górny róg). Aby zobaczyć, co potrafi optymalizacja, posłużmy się prostą pętlą:
var
i: Integer;
b: Byte;
begin
i := 0;
for b := 1 to 9 do
i := i + 3;
Result:=i;
end;
Powyższy kod nie robi nic innego, jak dodaje do zmiennej i 9 razy wartość 3. Jak wygląda kod pętli bez optymalizacji na procesorze?
6: for b := 1 to 9 do
mov byte ptr [ebp-$09],$01
7: i := i + 3;
add dword ptr [ebp-$08],$03
inc byte ptr [ebp-$09]
6: for b := 1 to 9 do
cmp byte ptr [ebp-$09],$0a
jnz -$0d
Jak widać na początku pod adres [ebp-$09] w pamięci wprowadzana jest wartość początkowa pętli (1). Następnie dodawana jest w adresie pamięci wartość 3 oraz inkrementowana wartość licznika pętli. Na koniec wykonywane jest porównanie wartości licznika znajdującego się we wskazanym miejscu pamięci z wartością 10 ($0a) i instrukcja skoku warunkowego wstecz, jeśli wynik porównania był fałszywy. Cały kod składa się z 5 instrukcji i odwołań do dwóch miejsc w pamięci odpowiadających dwóm użytym zmiennym.
Włączmy teraz optymalizację kodu i przebudujmy projekt. Oto wyniki działania, czyli ta sama pętla po optymalizacji:
6: for b:=1 to 9 do
mov al,$09
7: i := i + 3;
add edx,$03
6: for b := 1 to 9 do
dec al
jnz -$07
Już na pierwszy rzut oka widać, że wszystkiego jest jakby mniej. Co się stało? Po pierwsze, zamiast pracować na wolnej pamięci operacyjnej, kod został zapisany z użyciem szybkich rejestrów procesora. Drugą rzeczą, która została zoptymalizowana, jest to, iż licznik pętli (tutaj rejestr AL) wcale nie zmienia się od 1 do 9, lecz od 9 do 1! A w zasadzie do zera. Dzięki temu możliwe było pozbycie się jednego rozkazu porównania. Dzieje się tak dlatego, gdyż wszelkie instrukcje arytmetyczne także dokonują ustawienia flagi ZF (Zero Flag), a właśnie jej ustawienie jest głównym zadaniem instrukcji porównania CMP. Optymalizacja taka była możliwa z uwagi na fakt, że licznik pętli w żaden sposób nie jest wykorzystany w jej środku, stąd jego wartość nie ma znaczenia dla przebiegu pętli.
Ponadto optymalizacja potrafi eliminować z kodu "bezużyteczne" polecenia (np. przypisania wartości do zmiennych, które nigdy nie zostaną odczytane).
Pozostałe opcje kompilatora
Poza optymalizacją kompilator posiada jeszcze wiele innych parametrów, które będą miały wpływ na wydajność wygenerowanego kodu. Opiszę niektóre z nich. Można je też znaleźć w oknie ustawień projektu pokazanym na rys. 1. Po myślnikach podano wartość, która pozytywnie wpłynie na wydajność kody (często jest to wartość domyślna).
- Podstawianie treści funkcji w miejscu wywołania (Code inlining control) –
{$INLINE AUTO} – pozwala na wstawianie zawartości funkcji w miejscu jej użycia. Temat bardziej szczegółowo zostanie omówiony w dalszej części.
- Minimalny rozmiar listy wyliczeniowych (Minimum enum size) –
{$Z4} – określa, na jaki typ mają być zamienione wszystkie elementy wyliczeniowe. Stanem domyślnym jest {$Z1}, który oznacza, że elementy w listach do 256 elementów zostaną zapisane jako zmienne typu byte, do 64k, jako zmienne typu word. Jak będzie można dowiedzieć się z dalszej części artykułu, szczególnie ten drugi przypadek jest bardzo niepożądany. Dlatego warto zastosować przełącznik {$Z4}, który sprawi, że wszystkie elementy zostaną zamienione na najwydajniejszy typ, jakim jest Integer.
- Optymalizacja (Optimization) –
{$O+} – ta flaga została opisana dokładnie w poprzedniej części artykułu.
- Wyrównanie pól rekordów (Record field alignment) –
{$A+} – dzięki temu ustawieniu kompilator dokona wyrównania wszystkich pól do wskazanej wielkości. Domyślną wartością jest 8 bajtów ({$A8}). Oznacza to, że wszystkie zmienne w rekordach i klasach będą miały wielkość 8 bajtów lub jej wielokrotność (o ile nie użyto słówka packed), co z jednej strony spowoduje zwiększenie pliku wynikowego oraz zapotrzebowania na pamięć, ale z drugiej przyspieszy dostęp do tych danych. Takie jest też ustawienie domyślne.
- Ramki stosu (Stack frames) –
{$W-} – opcja ta określa sposób obsługi zmiennych lokalnych we funkcjach; włącznie powoduje, że zawsze dane zostaną odłożone na stos. Takiego działania wymagają niektóre debuggery, lecz takie działanie zwiększa ilość poleceń procesora dla generowanego kodu i to o powolne operacje na stosie.
- Asercje (Assertions) –
{$C-} – specjalnie na potrzeby debugowania wymyślony został mechanizm asercji. Jest to funkcja Assert(...), w której parametrach podajemy warunek logiczny, jaki musi być spełniony. Jeśli tak nie jest, wywołany zostanie wyjątek EAssertionFailed. Z asercjami często można spotkać się w kodzie komponentów. Wyłączenie wspomnianej opcji sprawi, że taki kod zostanie zupełnie pominięty przez kompilator (tak, jakby go w ogóle nie było).
- Kontrola operacji wejścia/wyjścia (I/O checking) –
{$I-} – Włączenie tego przełącznika spowoduje, że program po każdej procedurze wejścia/wyjścia (np. otwarcie pliku) będzie sprawdzał wartość zwracaną przez system Windows i w przypadku wystąpienia wartości niezerowej zostanie wygenerowany wyjątek. Wyłączenie opcji z pewnością wpłynie pozytywnie na wydajność oraz umożliwi rezygnację z czasochłonnych bloków try..except, lecz stwarza zagrożenie dla stabilności aplikacji i systemu w przypadku nie obsłużenia błędu. Dlatego gdy ta opcja jest wyłączona, należy samemu zadbać o badanie stanu zwrotnego operacji I/O poprzez funkcję IOResult.
- Sprawdzanie przepełnień (Overflow checking) –
{$Q-} – włączenie tej opcji sprawi, że wszystkie operacje arytmetyczne stałoprzecinkowe będą badane pod kątem wystąpienia przekroczenia zakresu. W takiej sytuacji wygenerowany zostanie wyjątek. Choć sprawia to, że kod staje się znacznie bardziej bezpieczny, to jednak w zdecydowanej większości przypadków programista sam potrafi przewidzieć możliwe wyniki i sam dobierze właściwie rozmiar zmiennych lub zabezpieczy kod w inny sposób. Dlatego sprawdzanie przekroczenia zakresu jest tylko marnowaniem czasu. Jednak jeśli opcja ta jest wyłączona, a dojdzie do przekroczenia zakresu, to wynik zostanie „zawinięty” (stracony zostanie najstarszy bajt, który nie zmieścił się w zakresie). Warto dodać, że czasem jest to wykorzystywane umyślnie (np. kodowanie znaków Szyfrem Cezara).
- Sprawdzanie zakresów (Range checking) –
{$R-} – podobną funkcję do poprzedniej pełni to ustawienie. Jeśli jest włączone, wówczas program będzie sprawdzał, czy nie przekroczymy zakresu indeksu tablic lub ciągów znakowych, a w przypadku wystąpienia takiej sytuacji zostanie wygenerowany wyjątek. Nie trzeba dodawać, że dość mocno może to spowolnić kod, mimo iż czyni go bezpieczniejszym.
- Skracanie warunków logicznych (Complete boolean evaluation) –
{$B+} – ta flaga sprawia, że warunki logiczne połączone operatorem and będą sprawdzane tak długo, aż wystąpi pierwszy fałszywy, zaś w przypadku operatora or - do momentu, aż wystąpi pierwszy prawdziwy. Dzięki temu procesor nie będzie marnował czasu na sprawdzanie pozostałych, które i tak nie zmienią wyniku operacji logicznej. Takie ustawienie jest domyślne. Kiedy więc wyłącza się tą opcję? A mianowicie, gdy np. jeden z argumentów w całym ciągu jest np. funkcją, która zawsze musi być wywołana, a nie jest umieszczona na początku. Wyłączenie bowiem spowoduje, że wszystkie funkcje w ciągu warunków logicznych zostaną wywołane.
Właściwe zapisywanie warunków
Bardzo często w kodzie programu można znaleźć tego typu zapisy:
if i >= 1 then
b := True
else
b := False;
Powyższy kod przekłada się na następujący:
1: if i >= 1 then
dec eax
jnz +$04
2: b := True;
mov bl,$01
jmp +$02
4: b := False
xor ebx,ebx
Jest to często popełniany błąd optymalizacyjny. Warto skorzystać z możliwości przypisywania wyniku warunku wprost do zmiennej. Jest jeszcze jedno miejsce do optymalizacji. Gdzie tylko to możliwe, powinniśmy dążyć do porównań wszelkich wartości z liczbą zero. Jest to spowodowane dokładnie tym samym, o czym zostało wspomniane w poprzednim punkcie. Tak więc nasz kod po optymalizacji będzie miał następującą postać:
b := i > 0;
A kompilator wygeneruje następujący kod:
1: b := i > 0
test eax,eax
setnle bl
Jak widać z pięciu instrukcji zrobiły się dwie. Co więcej, gdyby przed warunkiem było jakieś obliczenie liczby i, wówczas polecenie test mogło by okazać się zbyteczne!
Z tego samego tytułu wszelkie pętle for, o ile te możliwe, powinny iść w dół (for..downto) i kończyć się na wartości 1 (gdyż kolejny przebieg powoduje zmniejszenie do wartości 0 i wówczas można wprost zastosować instrukcję skoku warunkowego).
Warto w tym punkcie wspomnieć jeszcze o wielu warunkach w funkcji if. Zasada jest taka, że przy złączeniu alternatywą or na początku powinien występować najczęściej spełniany warunek (gdyż spełnienie pierwszego powoduje, że nie ma potrzeby sprawdzania pozostałych), zaś w przypadku iloczynu logicznego and na początku powinien być ten warunek, które spełniany jest w najmniejszej liczbie przypadków (z tego samego tytułu, co wcześniej).
Często popełnianym błędem z punktu widzenia wydajności jest nieużywanie słowa kluczowego else pomiędzy warunkami wzajemnie się wykluczającymi. Jeśli więc mamy kod:
if i > 50 then Instrukcja1;
if i < 10 then Instrukcja2;
Procesor komputera najpierw sprawdzi pierwszy warunek i w przypadku jego spełnienia wywoła funkcję. Następnie zostanie sprawdzony drugi warunek mimo, iż nie może on zaistnieć, jeśli pierwszy był już spełniony. Dlatego należy dodać słówko else:
if i > 50 then Instrukcja1;
else if i < 10 then Instrukcja2;
Kolejnym często popełnianym błędem ze względu na optymalizację kodu, jest używanie słowa kluczowego not w intrukcjach warunkowych posiadających klauzulę else. Choć nowe wersje kompilatorów potrafią sobie z tym poradzić, to jednak warto wyrobić sobie nawyk i wszystkie takie wystąpienia z powodzeniem zastąpić eliminując intrukcję negacji i zamieniając miejscami kod podwarunkowy:
if not Math.IsZero(a) then
writeln('a NIE jest zerem!')
else
writeln('a jest zerem!');
Optymalna postać kodu powinna wyglądać tak:
if Math.IsZero(a) then
writeln('a jest zerem!')
else
writeln('a NIE jest zerem!');
Jak widać w prosty sposób pozbyliśmy się jednej, zupełnie niepotrzebnej instrukcji.
Instrukcja case
Bardzo istotnym zagadnieniem dotyczącym warunkowego sterowania przepływem programu jest korzystanie z instrukcji case. To, jak kompilator Delphi przekształca ją na kod procesora jest zagadnieniem bardzo złożonym. Najpierw kompilator sortuje wszystkie wartości/zakresy. Płynie stąd wniosek, że kolejność zapisanych wartości nie ma żadnego znaczenia. Następnie budowana jest struktura drzewa binarnego, czyli stosowany będzie algorytm wyszukiwania binarnego. Jest to bardzo istotne z punktu widzenia optymalizacji wydajnościowej. Ale uwaga – takie drzewo zostanie zbudowane wyłącznie wtedy, gdy współczynnik gęstości na to pozwala. Jeśli rozrzut jest duży – lista dzielona jest na połowy i każda z nich przeszukiwana niezależnie. Dlatego dobrym sposobem na pomoc kompilatorowi jest pogrupowanie warunków wg zakresów. Kod:
case c of
'a': proc1;
'b': proc2;
'c': proc3;
'd': proc4;
'e': proc5;
'A': proc101;
'B': proc102;
'C': proc103;
'D': proc104;
'E': proc105;
end;
Należy zamienić na:
case c of
'a'..'e': case c of
'a': proc1;
'b': proc2;
'c': proc3;
'd': proc4;
'e': proc5;
end;
'A'..'E': case c of
'A': proc101;
'B': proc102;
'C': proc103;
'D': proc104;
'E': proc105;
end;
end;
Jeśli jakiś warunek dodatkowo spełniany jest dużo częściej, niż pozostałe, warto wysunąć go przed instrukcję case:
if c = 'E' then proc105
else case c of
…
Praca ze zbiorami
Język Pascal udostępnia nam niezwykle wygodne narzędzie w postaci zbiorów elementów typu wyliczeniowego. Dzięki nim zamiast wykonywać sprawdzenie, czy znak jest jednym z przewidzianych znaków, poprzez zastosowanie rozbudowanej konstrukcji or
if (c = 'a') or (c = 'A') or (c = #27) or (c = #13) then …
Można zastosować znacznie czytelniejszą instrukcję:
if c in ['a', 'A', #27, #13] then …
Wydajność obu rozwiązań może być zróżnicowana w zależności od prawdopodobieństwa spełnienia lub nie poszczególnych warunków. Jednak przy równomiernym rozkładzie oba rozwiązania będą porównywalne. Należy zwrócić przy tym uwagę, że dla konstrukcji z or kolejność zapisów ma znaczenie; w przypadku zbioru i operatora in nie ma znaczenia kolejność podania elementów zbioru.
Praca ze zbiorami jest na pewno wygodniejsza, a kod zyskuje na czytelności. Czasem ich użycie może być też konieczne. Dokonując operacji na zbiorach należy pamiętać, że dodając lub usuwając elementy ze zbioru zamiast używania operatorów plus (+) i minus (-), powinno się korzystać z funkcji Include i Exclude, które działają znacznie szybciej. Nawet, jeśli chcemy dodać lub odjąć zbiór pokrywający prawie cały zakres, wielokrotne użycie podanych funkcji będzie bardziej wydajne, niż dodawanie lub odejmowanie zbioru.
Podczas deklarowania danych wyliczeniowych kompilator w tle sam przydziela odpowiednim zapisom poszczególne wartości numeryczne. Stosuje przy tym możliwie najmniejszy typ danych. Niestety w przypadku typów wyliczeniowych o rozmiarze ponad 255 elementów, a mniej niż 65535 stosowany jest powolny typ Word. Należy więc bezwzględnie posłużyć się dyrektywą {$Z+} aby wymusić typ 32-bitowy. O tym, dlaczego tak się dzieje, napisane będzie w dalszej części poradnika.
Zmienne
W punkcie tym pragnę poruszyć dwa zagadnienia. Pierwszym z nich jest używanie zmiennych globalnych i lokalnych. Zmienne lokalne to wszystkie te, które definiowane są w argumentach lub wewnątrz procedur i funkcji. Należy kategorycznie rezygnować ze stosowania zmiennych globalnych, chyba że jest to absolutnie niezbędne. Wymóg ten podyktowany jest faktem, iż wyłącznie zmienne lokalne mogą być przekształcone w zmienne rejestrowe. Dlatego często dobrym rozwiązaniem jest przepisanie zmiennej globalnej do zmiennej lokalnej na czas wywoływania funckji, szczególnie jeśli taka zmienna użyta jest w pętlach. Pola klasy także należy traktować jak zmienne globalne. Od tej reguły jest jednak wyjątek. Jeśli mamy tablicę o stałym rozmiarze i stałych elementach prostych lub strukturalnych, to tutaj wydajniejsze okaże się zdefiniowanie jej jako zmiennej globalnej, niż przekazywanie do funkcji.
Druga sprawa dotyczy właściwego doboru typu zmiennych. Skupmy się na zmiennych całkowitych. Delphi oferuje kilkanaście typów: zmienne 8-, 16-, 32- i 64-bitowe. Są dwa podejścia programistów – jedni zupełnie nie zwracają uwagi na stosowany typ i wszędzie wrzucają standardowy Integer; drudzy stosują w każdej sytuacji najmniejszy z możliwych typów. Wbrew pozorom, pierwsze podejście jest lepsze! Tym, czego powinniśmy się wystrzegać, to stosowanie typów 16-bitowych. Operacje wykonywane na tych typach wiążą się koniecznością przełączenia procesora w tryb 16-bitowy, co negatywnie wpływa na wydajność. Takich problemów nie obserwuje się w przypadku korzystania z typów 8-bitowych. Ich stosowanie jest wskazane, gdyż operacje przeprowadzane są szybko, a jednocześnie zajmują mniej w pamięci. Unikać należy także typu 64-bitowego w kompilacjach 32-bitowych z prostej przyczyny – jest to tylko emulacja. Nie ma to zastosowania do kodu skompilowanego jako 64-bitowego (od wersji kompilatora XE2 lub nowszej). Jeśli możemy sobie pozwolić na różny rozmiar, a jednocześnie chcemy utrzymać kod wydajnym na każdej z architektur, możemy posłużć się typem NativeInt i pokrewnymi, której długość jest różna w zależności od platformy docelowej.
To, czego należy się wystrzegać ponadto, to mieszanie typów. Operacje wykonywane na obu typach równocześnie będą wymagały dokonania rzutowania na typ większy. Dla przykładu kod:
var
b: byte;
i: Integer;
begin
…
for b := 255 downto 1 do
Inc(i, b);
Zostanie zamodelowany na procesorze w następujący sposób:
5: for b := 255 downto 1 do
mov al,$ff
6: Inc(i, b);
movzx ecx,al
add edx,ecx
dec eax
5: for b := 255 downto 1 do
test al,al
jnz -$0b
Jak widać operacja inkrementacji złożyła się z kilku etapów – przygotowania rejestru, przeniesienia wartości i dodania właściwego. Prosta zamiany typu zmiennej b z byte na Integer (a więc ten sam, co zmiennej i) daje takie oto rezultaty:
5: for b:=255 downto 1 do
mov eax,$000000ff
6: Inc(i,b);
add edx,eax
dec eax
5: for b:=255 downto 1 do
test eax,eax
jnz -$07
W ten sposób pozbyliśmy się jednego polecenia odpowiedzialnego za rzutowanie i zwolniliśmy jeden rejestr procesora z użytku. Nadmienię, że w strszych wersjach komilatorów (np. Delphi 7) takie rzutowanie mogło odbyć się z wykorzystaniem aż dwóch poleceń procesora.
Warto zaznaczyć, że jeśli z jakiegoś względu nie możemy z góry zastosować identycznych typów zmiennych, to warto przed wykonywaniem wielokrotnych obliczeń dokonać samemu zrzutowania poprzez przepisanie zmiennej typu 8- lub 16-bitowego na typ Integer.
Nieco inaczej sprawa ma się ze zmiennymi zmiennoprzecinkowymi. Tutaj rozmiar zmiennej ma znaczenie głównie przy przesyłaniu danych z i do FPU. Jednakże jednostka FPU dokonuje obliczeń zawsze w pełnym możliwym zakresie dokładności. Mało kto wie, ale możemy ograniczyć tą dokładność, zyskując przy tym sporo na wydajności operacji dzielenia. Służy do tego funkcja SetPrecisionMode z unitu Math. Przyjmuje ona jeden z trzech parametrów decydujący o precyzji obliczeń. Zamiast niej, znacznie szybciej można przestawić tryb korzystając z procedury Set8087CW lub dostępnej od Delphi 6 SetPrecisionMode z prostszą składnią. Zainteresowanych odsyłam do pomocy Delphi oraz danych w Internecie, które opisują przykład użycia.
Także przy obliczeniach na jednostce FPU należy dbać o to, aby nie mieszać różnych typów zmiennych, gdyż spowoduje to tak samo konieczność ich konwersji (znacznie bardziej czasochłonną, niż w przypadku konwersji liczb stałoprzecinkowych).
Na koniec warto wspomnieć o znów mało znanej możliwości wymuszania typów stałych. Jeśli nie określimy typu stałej, Delphi sam określi jej typ na podstawie jej wartości. Może okazać się to bardzo niewskazane. Dlatego każdorazowo deklarując stałe powinno określać się ich typ taki, jaki będzie wykonywany przy obliczeniach:
const
i: integer = 2;
pi: single = 3.14;
Przechodząc do kolejnego zagadnienia, pragnę zwrócić uwagę na pewną często ignorowaną rzecz: mianowicie używanie własności obietków (property) jak najzwyklejszych zmiennych. Tymczasem pobranie lub ustawienie wartości to najczęściej wywołanie metody (lub przynajmniej odczyt z pamięci). O tym, dlaczego należy tego unikać, napiszę w kolejnym punkcie, a tymczasem przeanalizujmy najczęściej występujące przypadki i popełniane błędy.
Załóżmy kod, gdzie w zależności od wyniku funkcji ustawimy widoczność kontrolki oraz wywołamy funkcję. Najczęściej kod taki będzie wyglądał w następujący sposób:
obj.visible := fn();
if obj.visible then
p();
To, na co należy zwrócić uwagę, to fakt, że w warunku na nowo pobieramy wartość właściwości obiektu. Tym czasem my ja znamy! Ale kompilator niepotrzebnie wygeneruje wywołanie funkcji w celu dostarczenia wartości. Jak zatem powinien wyglądać poprawny i bardziej wydajny kod? Wystarczy wprowadzić zmienną!
var
b: Boolean;
...
b := fn();
obj.visible := b;
if b then
p();
Widać tu, że najpierw w zmiennej zapamiętamy wynik i to własnie ona posłuży zarówno do ustawienia własności kontrolki jak i sprawdzenia warunku. W ten sposób pozbywamy się konieczności pobrania wiadomiej wartości.
pbProgressBar1.Progress := pbProgressBar1.Progress + 1;
gGauge1.Progress := gGauge1.Progress + 1;
Tymczasem obie użyte kontrolki posiadają medoty, dzięki którym nie musimy pobierać aktualnej wartości pola Progress:
pdProgressBar1.StepIt;
gGauge1.AddProgress(1);
Warto więc zainteresować się tym, co dostarcza obiekt, a tworząc własne zapewnić metody, które zminimalizują potrzebę pobierania wartości.
Bardzo podobnym a często występującym przykładem nieoptymalnego użycia własności obiektu jest zwiększanie postępu dla pasków postępu:
Wywoływanie funkcji i ich parametry
Każde wywołanie funkcji wiąże się z dość sporym kosztem. Choć funkcje pozwalają na lepsze gospodarowanie pamięcią, zmiennymi i rejestrami, a także upraszczają kod, to jednak samo ich wywołanie trwa dość długo. Dlatego należy unikać stosowania wszelkich funkcji przede wszystkim w newralgicznych pętlach i zastępować je treścią funkcji. W nowszysch wersjach Delphi możliwe jest zachowanie czytelności funkcji przy jednocześnie utrzymanej wysokiej wydajności kodu - służy do tego modyfikator inline umieszczany tuż za nagłówkiem funkcji. Pamietać jednak musimy także o włączeniu właściwej opcji projektu:
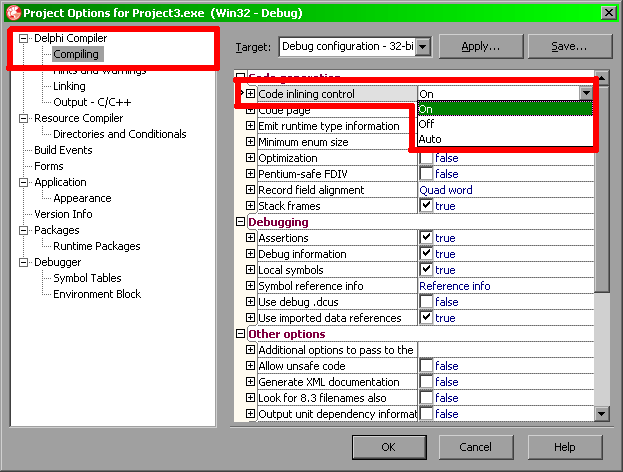
Wartość On pozwoli na przekształcenie funckji z dyrektywą inline na "czysty" kod. Ciekawą jest wartość Auto, która sprawia, że wszystkie małe funkcje (o rozmiarze poniżej 32 bajtów) zostaną automatycznie potraktowane tak, jakby posiadały modyfikator inline.
Niestety, stosowanie tej sztuczki jest ograniczone i nie każda procedura czy funkcja może być przekształcona w ten sposób. O ewentualnym braku możliwości poinformuje kompilator. Nadmienić tylko warto, że limity przedstawiają się różnie dla róznych platform, zatem warto być może używać dyrektywy inline warunkowo (a więc np. w dyrektywnie kompilatora {$IFDEF WIN64}inline;{$ENDIF}).
Delphi pozwala na stosowanie dość specyficznego tworu, jakim jest funkcja zagnieżdżona (lokalna). Może wydawać się to interesującym rozwiązaniem: Funkcje zagnieżdżone nie są widoczne dla innych funkcji, a jednocześnie wszelkie zmienne, stałe i typy funkcji zewnętrznych (zadeklarowane przed funkcją wewnętrzną) stają się widoczne dla funkcji wewnętrznych. Przykładem niech będzie taka oto konstrukcja:
function Test(i, w: Integer): Integer;
procedure Wew;
var
x: Integer;
begin
for x := 1 to w do
i := i div 3;
end;
var
b: integer;
begin
for b := i to 255 do begin
Wew;
Inc(i, w);
end;
Result := i;
end;
Stosowanie tego typu dziwolągów powoduje duży bałagan dla procesora. Zarządzanie stosem i przekazywanie parametrów jest w tym momencie niezwykle skomplikowanym przedsięwzięciem. Tak oto wygląda kod funkcji testowej wraz z funkcją wewnętrzną i jej wywołaniem:
2: begin //procedure Wew
push ebp
mov ebp,esp
push ebx
3: for x := 1 to w do
mov eax,[ebp+$08]
mov ebx,[eax-$04]
test ebx,ebx
jle +$50
4: i := i div 3
mov eax,[ebp+$08]
mov ecx,$00000003
add eax,-$08
push eax
mov eax,[eax]
cdq
idiv ecx
pop edx
mov [edx],eax
3: for x := 1 to w do
dec ebx
jnz -$15
5: end //procedure Wew
pop ebx
pop ebp
ret
8: begin //function Test
push ebp
mov ebp,esp
add esp,-$08
push ebx
mov [ebp-$04],edx
mov [ebp-$08],eax
9: for b := i to 255 do begin
mov ebx,[ebp-$08]
cmp ebx,$000000ff
jnle +$16
10: Wew
push ebp
call Wew
pop ecx
11: inc(i,w)
mov eax,[ebp-$04]
add [ebp-$08],eax
9: for b := i to 255 do begin
inc ebx
cmp ebx,$00000100
jnz -$14
14: Result := i
mov eax,[ebp-$08]
Na cały kod złożyło się 39 instrukcji.
Należy bezwzględnie unikać takiego zapisu. Wszystkie funkcje lokalne można wynieść na zewnątrz wraz z potrzebnymi typami. Wszelkie stałe i zmienne można przekazać przez parametr. Tak oto wygląda program po wyniesieniu funkcji wewnętrznej na zewnątrz:
procedure Wew(var i, w: Integer);
var
x: Integer;
begin
for x := 1 to w do
i := i div 3;
end;
function Test(i, w: Integer): Integer;
var
b: integer;
begin
for b := i to 255 do begin
Wew(i, w);
Inc(i, w);
end;
Result := i;
end;
A tak przedstawia się na procesorze:
4: begin //Wew
push ebx
push esi
mov esi,eax
5: for x := 1 to w do
mov ebx,[edx]
test ebx,ebx
jle +$0f
6: i := i div 3
mov ecx,$00000003
mov eax,[esi]
cdq
idiv ecx
mov [esi],eax
5: for x := 1 to w do
dec ebx
jnz -$0b
7: end //procedure Wew
pop esi
pop ebx
ret
12: begin //function Test
push ebx
add esp,-$08
mov [esp+$04],edx
mov [esp],eax
13: for b := i to 255 do begin
mov ebx,[esp]
cmp ebx,$000000ff
jnle +$1a
14: Wew
lea edx,[esp+$04]
mov eax,esp
call Wew
15: inc(i, w)
mov eax,[esp+$04]
add [esp],eax
13: for b := i to 255 do begin
inc ebx
cmp ebx,$00000100
jnz -$1b
18: Result := i
mov eax,[ebp-$08]
Jak widać liczba instrukcji spadła z 39 do 32, przy czym tych związanych z samym wywołaniem funkcji lokalnej ubyło z 13 do 9, w tym liczba czasochłonnych operacji na stosie związanych z wywołaniem funkcji spadła z 8 do 4, czyli aż o połowę! Mało tego, jak widać kod został znacznie lepiej zoptymalizowany i mniej jest odwołań do pamięci z przesunięciem. Tak więc zyski z zamiany funkcji lokalnej na funkcję zewnętrzną są nie do przecenienia. A przy wykorzystaniu większej liczby zmiennych rezultaty będą jeszcze bardziej zachęcające. Korzyści te gołym okiem dają się zauważyć także po czasie wywoływania procedury (tej przedstawionej już przy około 1000 wywołań procedury Test).
Skoro jesteśmy już przy wywoływaniu funkcji, to kolejnym aspektem, który należy poruszyć mówiąc o projektowaniu wysokowydajnego kodu, to sposób przekazywania parametrów. Magiczną granicą są tutaj 3 parametry, gdyż taka ich ilość może być przekazana przez rejestry. Każde kolejne parametry będą przekazywane z użyciem powolnego stosu. Nie należy zapominać przy tym, że wszystkie metody klas otrzymują niewidoczny parametr Self.
Projektując argumenty funkcji należy unikać, gdzie tylko to możliwe, przekazywania tychże parametrów przez wartość. Początkujący programiści Delphi często znają tylko dwa rodzaje przekazywania parametrów – właśnie przez wartość oraz przez referencję (var). Tymczasem Delphi pozwala także na przekazywanie parametrów przez stałą (const) oraz definiuje parametr jako wyjściowych (out). Dzięki właściwemu wykorzystaniu tych modyfikatorów kod będzie mógł być znacznie lepiej zoptymalizowany przez kompilator. W rzeczywistości w większości przypadków modyfikatory const i out zachowają się identycznie, jak przy przekazywaniu przez typową referencję. Różnica polega głównie na tym, że zmiennej poprzedzonej modyfikatorem const nie będziemy mogli zmodyfikować w ciele funkcji.
Aby zobaczyć, jak duże oszczędności może przynieść pozbycie się przekazywania przez wartość, przeanalizujmy funkcję, która przyjmie dwa parametry: pierwszy z nich będzie ciągiem tekstowym, w drugim będzie zwracana długość tego ciągu. Początkujący programista zapisze funkcję zapewne w taki sposób:
Procedure MyLen(S: String; var Len: Integer);
begin
Len := Length(S);
end;
Tak więc mamy przekazany parametr pierwszy przez wartość, a drugi przez referencję. Tak oto zostanie odwzorowany ten kod:
2: begin
push ebp
mov ebp,esp
push ecx
push ebx
mov ebx,edx
mov [ebp-$04],eax
mov eax,[ebp-$04]
call @LStrAddRef
xor eax,eax
push ebp
push $00408188
push dword ptr fs:[eax]
mov fs:[eax],esp
3: len:=Length(S)
mov eax,[ebp-$04]
test eax,eax
jz +$05
sub eax,$04
mov eax,[eax]
mov [ebx],eax
4: end
xor eax,eax
pop edx
pop ecx
pop ecx
mov fs:[eax],edx
push $0040818f
lea eax,[ebp-$04]
call $LStrClr
ret
Analizując naszą funkcję można zauważyć, że zmienna S nie jest modyfikowana, dlatego warto określić ją jako stałą (const). Drugi parametr służy wyłącznie do zwracania wartości, stąd zasadniczo lepiej określić go jako wyjściowy (out). Choć w przypadku typów prostych ta zmiana nie będzie miała znaczenia, to jednak sprawi, że kod będzie bardziej czytelny. Jednakże są przypadki, gdy użycie tego modyfikatora jest zasadne. Po szczegóły odsyłam do pomocy Delphi. Procedura po modyfikacjach będzie miała następujący nagłówek:
Procedure MyLen(const S: String; out Len: Integer);
A tak zaprezentuje się kod wynikowy po jej zmodyfikowaniu:
3: Len := Length(S)
test eax,eax
jz +$05
sub eax,$04
mov eax,[eax]
mov [edx],eax
4: end
ret
Jak widać różnica jest diametralna! Choć parametry typu string są bardzo wrażliwe na takie modyfikacje i dają zauważalne efekty, to jednak warto używać ich także wobec typów prostych. Zyska na tym nie tylko wydajność, ale i czytelność kodu.
Przy okazji omawiania procedur, a ściślej – metod, nie sposób nie wspomnieć o metodach dynamicznych lub wirtualnych. Metody (czyli procedury i funkcje klasy), po których występuje słowo dynamic lub virtual mogą zostać nadpisywane w klasach potomnych, w przeciwieństwie do metod statycznych. Zarówno metody dynamiczne i wirtualne są semantycznie identyczne. Różnicą jest to, że metody oznaczone słowem virtual zoptymalizowane są pod kątem wydajności kodu, zaś te z dopiskiem dynamic będą zajmować mniejszą ilość kodu, a więc oszczędzą pamięć.
Arytmetyka w Delphi
Bardzo często w kodach można spotkać zapisy:
i := i + 1
Choć w większości przypadków optymalizator poradzi sobie z tym zapisem, to jednak powinniśmy dążyć do operowania na instrukcjach inc i dec (oczywiście zakładając, że liczba i jest liczbą całkowitoliczbową). Dzięki nim mamy pewność, że zwiększenie lub zmniejszenie wartości zajmie zawsze tylko jedną instrukcję w języku procesora.
Warto także zwrócić uwagę na operacje mnożenia i dzielenia przez 2 lub jej potęgę (4, 8, 16 itd.) liczb całkowitoliczbowych dodatnich(!). Okazuje się, że operacje te są bardzo wolne w porównaniu do efektu ich działania. Mnożenie przez 2 to nic innego, jak przesunięcie bitowe o 1 bit w lewo. Zaś dzielenie całkowitoliczbowe to to samo, co przesunięcie bitowe o jeden bit w prawo. Dlatego kod:
i := a * 2;
j := j div 2;
Należy zastąpić kodem:
i := a shl 1;
j := j shr 1;
Także dzielenie modulo (czyli optrzymywanie reszty z dzielenia) przez wielokrotność liczby 2 można z powodzeniem zastąpić operacją mnożenia binarnego przez maskę o wartości równej wartości dzielnika pomniejszoną o 1. Dlatego kod:
a := b mod 4
Zastępuje się kodem:
a := b and 3; //4 - 1 = 3; binarnie: 00000011b
Generalnie warto pamiętać, że wszystkie operacje bitowe (przesunięcia, mnożenia, sumy itp.) są najszybszymi z możliwych operacji.
Skoro już jesteśmy przy wydajności operacji, warto wspomnieć, że operacja dzielenia jest najbardziej obciążającą procesor. Wszędzie, gdzie to możliwe, powinniśmy dążyć do zastąpienia jej operacją mnożenia przez odwrotność. Przykładowo kod:
i := a / 5;
Powinniśmy zastąpić kodem:
i := a * 0.2;
Warto w tym miejscu przypomnieć, że jeżeli w pewnym kodzie programu wykorzystujemy identyczną operację arytmetyczną w kilku miejscach, która daje ten sam wynik, to lepiej tenże zapamiętać w dodatkowej zmiennej, a następnie wykorzystywać właśnie tą zmienną, zamiast powtarzać operację. Nie należy jednak przesadzić. Optymalną liczbą zmiennych jest nie więcej niż 8, gdyż taka ich liczba może być używana z wykorzystaniem rejestrów procesora. Warto więc zbadać, czy zapisanie w pamięci wyniku prostego dodawania i wykorzystanie go w dwóch miejscach nie będzie przypadkiem wolniejsze, niż pozostawienie tych obliczeń bez modyfikacji.
Wykorzystajmy więc tą wiedzę do rozwiązania typowego problemu...
Kolorowanie co drugiego wiersza komponentu TListView
Zapewne często zdarza się, że chcemy urozmaicić zestawienia i stosujemy komponent TListView w stylu raportu (lub jakikolwiek inny tabelaryczny), w których chcemy wyszarzyć lub pokolorować co drugi wiersz. Najczęściej kod wygląda w ten sposób:
procedure TForm1.ListView1CustomDrawItem(Sender: TCustomListView;
Item: TListItem; State: TCustomDrawState; var DefaultDraw: Boolean);
begin
with Sender.Canvas.Brush do begin
if Item.Index mod 2 = 1 then
Color := clSilver
else
Color := clWhite;
end;
end;
Jako, że przerysowania i wykorzystanie tej procedury obsługi zdarzenia jest bardzo częste, wysoka wydajność jej działania jest niezbędna! W kodzie tym widzimy aż kilka niedoskonałości. Po pierwsze - zupełnie niepotrzebne zastosowanie klauzuli with. Dlaczego? O tym napiszę nieco dalej. Po drugie, jak wspomniałem wcześniej dzielenie modulo należy zastąpić operacją bitową. Po trzecie, nie należy przyrównywać do wartości innej niż 0, jeśli nie jest to konieczne. Jak więc będzie wyglądał nasz optymalny i szybki kod po tych trzech zmianach?
procedure TForm1.ListView1CustomDrawItem(Sender: TCustomListView;
Item: TListItem; State: TCustomDrawState; var DefaultDraw: Boolean);
begin
// Rezygnacja z niepotrzebnego with
if Item.Index and 1 = 0 then //zastąpienie operacji MOD operacją AND oraz przyrównanie do 0, jako szybsza operacja
Sender.Canvas.Brush.Color := clWhite // Z powodu zmiany przyrównania w warunku, zamienione zostały miejscami kolory, aby wciaż dać ten sam efekt
else
Sender.Canvas.BrushColor := clSilver;
end;
Badanie wydajności pozostawiam czytelnikowi.
Operacje na łańcuchach (String)
Uwaga! Wszystkie wskazówki przedstawione w tym dziale dotyczą wyłącznie aplikacji środowiska Win32. Operacje na typie String w środowiskach .NET wykonuje się poprzez użycie klasy StringBuilder, która nie będzie omawiana w tym poradniku.
Dość często programiści dokonują łączenia stringów wykorzystując operator dodawania. Jest to faktycznie najbardziej optymalne rozwiązanie, a jednocześnie bardzo przejrzyste. Jednak sprawa zaczyna się komplikować, kiedy w ciąg wynikowy włączamy wartości zmiennych liczbowych, które są poddawane konwersji na łańcuch znaków. Często wówczas korzysta się z funkcji IntToStr. W Delphi w wersjach do 6.0 włącznie funkcja ta przykrywała standardową funckję Format. W nowszych środowiskach funkcje konwersji wartości zostały napisane od nowa z wykorzystaniem kodu niskopoziomowego, a w kolejnych przyspieszono. Dlatego w starych wersjach kompilatora, zamiast kodu:
S := 'Wykonano ' + IntToStr(i) + ' z ' + IntToStr(n) + ' zadań';
Znacznie szybsze w wykonaniu jest zapisanie tego kodu w postaci:
S := Format('Wykonano %d z %d zadań', [i, n]);
I o ile w starszych wersjach znacznie szybszą wersją będzie druga, to w najnowszych jest ręcz przeciwnie! Warto zatem przygotowując wydajny kod zadbać o każdą z wersji oddzielnie. Oczywiście funkcja Format może przyjmować nie tylko liczby całkowite, ale także zmiennoprzecinkowe o określonym formacie, czy ciągi tekstowe. Osoby, które zetknęły się z językiem C, z pewnością poczują się tu swobodnie. Reszcie polecam pomoc Delphi na temat tej funkcji.
Drugim istotnym zagadnieniem jest dołączanie do ciągu innego ciągu, bądź znaków. Szczególnie, jeśli taka operacja przeprowadzana jest w pętli, to zajmuje ona sporo czasu. Przeanalizujmy prostą funkcję kodującą:
function Code(const ToCode: String): String;
var
i: Integer;
begin
Result := '';
for i := 1 to Length(ToCode) do
Result := Result + Char(Ord(ToCode[i]) xor $99);
end;
Funkcja ta zamienia wszystkie znaki poddając je operacji logicznej na bitach – alternatywy rozłącznej (taka operacja jest odwracalna poprzez ponowne jej wywołanie). Jak widać, za każdym razem wynik jest doklejany do rezultatu, a więc potrzeba za każdym razem na nowo relokować pamięć dla rezultatu funkcji. Jako, iż z góry znamy rozmiar wyniku, znacznie szybciej jest przygotować od razu ciąg tekstowy odpowiedniej długości, a następnie podmieniać w nim wskazane znaki:
function Code2(const ToCode: String): String;
var
i: Integer;
begin
SetLength(Result, Length(ToCode));
for i := Length(ToCode) downto 1 do
Result[i] := Char(Ord(ToCode[i]) xor $99);
end;
Kod nie tylko zyskał na czytelności, ale także na szybkości działania. Dla ciągu o długości 20 znaków zanotowano wzrost wydajności aż 26-krotny! Ciekawych, skąd aż taki zysk, odsyłam do podglądu procesora i zwróceniu uwagi na realokację ciągu – w drugim przypadku wykonywana jest tylko jednorazowo alokacja pamięci. Dlatego czasem nawet bardziej opłacalne będzie początkowe przewymiarowanie wyniku, jeśli nie jesteśmy do końca pewni co do jego długości, a następnie obcięcie niepotrzebnej części funkcją Delete.
A skoro już przy tej funkcji, to warto zwrócić uwagę, że znacznie bardziej optymalne jest użycie właśnie jej, zamiast funkcji Copy jeżeli zależy nam na wyciągnięciu pewnego fragmentu tekstu.
Także do porównywania części ciągów pomiędzy sobą, nie warto używać funkcji Copy. Zamiast kodu:
if Copy(S1, 2, 7) = Copy(S2, 2, 7) then
Znacznie lepiej użyć takiego oto zapisu:
i := 2;
repeat
rowne := S1[i] = S2[i];
inc(i);
until (not rowne) or (i>8);
if rowne then …
Zastosowanie tego drugiego kodu dla porównania 20 elementów ciągu daje ponad 8-krotny zysk wydajności. Jeżeli pracujemy ze starszą wersją kompilatora, to jeszcze większy zysk możemy odnieść, jeśli semantycznego znaczenia zmiennej rowne użyjemy jej przeciwieństwa – zmiennej rozne oraz zamienimy porownanie na znak roznosci. Te zmiany pozwolą na wyrzucenie negacji z warunku pętli. Jednak uwaga – jeśli większość ciągów będzie różnych od siebie – wówczas lepszym podejściem okaże się pierwotne założenie. Na nowszych wersjach nie ma to znaczenia, gdyż wygenerowany kod będzie tak samo złożony.
Jak widać na tym przykładzie, nie tylko dobre zaprojektowanie algorytmu, ale także wiedza o częstości prawdopodobieństwa któregoś z wyników determinują wybór algorytmu, który pozwoli zbudować bardziej wydajny kod.
Jednak to nie koniec optymalizacji. Delphi dostarcza bowiem zupełnie inne rozwiązanie polegające nie na porównywaniu zmiennych, lecz porównywaniu dwóch obszarów pamięci. Wszystko sprowadza się do wskazania adresów, gdzie znajdują się ciągi i użycia super-szybkiej instrukcji CompareMem:
if CompareMem(@S1[2], @S2[2], 7 * SizeOf(Char)) then
W tym miejscu dwa słowa wyjaśnienia. Jak wspomniałem, funkcja bazuje na danych w pamięci. Dzięki temu może porównywać absolutnie dowolne, jednolite struktury. Z tego tytułu należy wskazać w pierwszych parametrach adres zmiennej. Służy do tego operator @ (jest to alias funkcji Addr), który właśnie zwraca adres. Jako, że typ string zapisany jest w pamięci jako ciąg następujących po sobie bajtów, przy czym pierwszym elementem tego typu jest wartość określająca długość, to należy wskazać, gdzie znajduje się początkowy znak, od którego chcemy dokonać porównania. Jeśli chcemy od pierwszego znaku, to należy użyć kodu @S[1]. W przykładzie badamy od 2 znaku do 8 (długość = 7), zatem potrzeba sprawdzenia od znaku 2 przez kolejnych 14 bajtów (jeśli String jest typu Unicode; najbezpieczniej zapisać jak w przykładzie: mnożąć ilosć znaków przez wielkość znaku w bajtach).
Jaki jest efekt zastosowanej optymalizacji? Kolejne blisko 6-krotne przyspieszenie działania! Jak widać, można bardzo dużo stracić na nieprzemyślanym porównywaniu części ciągów tekstowych.
Pętle
Analizując wcześniejsze kody pętli odwzorowywane na procesorze widać, że każda iteracja wiąże się ze sprawdzeniem wartości licznika. Tymczasem, jeśli znamy ilość iteracji pętli, możemy pokusić się o technikę tzw. skracania przebiegu pętli. Polega to na tym, że to, co oryginalnie było wykonywane w kilku iteracjach pętli, można wykonać w jednej iteracji. Załóżmy więc prosty przykład czyszczenia 256 elementowej tablicy:
var
tablica: array[0..255] of Integer;
i: integer;
begin
for i := 255 downto 0 do
tablica[i] := 0;
end;
Sama pętla (bez części inicjującej) wygląda następująco:
6: tablica[i] := 0
xor ebx,ebx
mov [ecx],ebx
sub eax,$04
5: for i := 255 downto 0 do
inc edx
jnz -$0a
Tak więc meritum pętli to 5 operacji powtarzanych w tym przypadku 256 razy czyli łącznie 1280 operacji.
Po zastosowaniu operacji skracania przebiegu kod Delphi wyglądać będzie następująco:
var
tablica: array[0..255] of Integer;
i: integer;
begin
i := 254;
while i > 0 do
begin
tablica[i] := 0;
tablica[i + 1] := 0;
dec(i, 2);
end;
end;
Na procesorze kod pętli przedstawia się następująco:
7: tablica[i] := 0;
xor ecx,ecx
mov [esp+eax*4],ecx
9: tablica[i+1]:=0;
xor ecx,ecx
mov [esp+eax*4+$04],ecx
10: dec(i, 2)
sub eax,$02
6: while i > 0 do
test eax,eax
jnle -$12;
Z pozoru większy kod, to 7 operacji na pętlę, ale zostanie ona wykonana wyłącznie 128 razy, a więc łącznie zostanie wykonanych 896 operacji. Choć odwołania są nieco bardziej skomplikowane, to także testy wydajnościowe potwierdzają ok. 30% zysk wydajności.
Warto zaznaczyć jednak, że technika ta ma zastosowanie dla pętli, w której liczba przebiegów jest wielokrotnością liczby naturalnej.
Wstawki asemblerowe
Panuje opinia, że zastosowanie kodu asemblera w programie sprawi, że algorytm stanie się szybszy. Jest to tylko połowiczna racja... Po pierwsze często kompilator jest w stanie stworzyć na tyle optymalny kod, że jego poprawienie staje się niemożliwe. Po drugie należy pamiętać, że kod maszynowy bardzo silnie związany jest z danym procesorem; to, co na jednym może okazać się wydajne, na innym będzie stanowić wąskie gardło aplikacji. Po trzecie projektując kod w asemblerze należy umieścić go z głową w całym kodzie. Często niewłaściwe umieszczenie prowadzi do spadku wydajności, gdyż optymalizator nie może wykorzystywać rejestrów użytych w kodzie asemblera i musi ich wartość na nowo inicjować przed wykorzystaniem. Oto prosty przykład (nie mający większego sensu logicznego):
procedure Test1(i: Integer; const j1, j2: Integer);
var
tablica: array[1..3] of Integer;
a, t: Integer;
begin
t := min(j1, j2);
for a := 3 downto 1 do
tablica[a] := 0;
inc(i, t);
inc(tablica[t], i);
end;
A tak oto odwzorowuje ten kod kompilator:
5: begin
push ebx
push esi
add esp,-$0c
6: t := min(j1, j2)
cmp ecx, edx
jnle +$04
mov edx,ecx
mov ebx,edx
8: for a := 3 downto 1 do
mov ecx,$fffffffd
lea edx,[esp+$08]
9: tablica[a] := 0;
xor esi,esi
mov [edx],esi
sub edx,$04
8: for a := 3 downto 1 do
inc ecx
jnz -$0a
11: inc(i, t);
add eax,ebx
12: inc(Tablica[t], i)
add [esp+ebx*4-$04],esi
13: end
add esp,$0c
pop esi
pop ebx
ret
Widać tutaj pewną możliwość zmiany – a mianowicie w pętli niepotrzebnie za każdym razem zerowany jest rejestr esi (nie ma żadnego polecenia, które mogło by zmienić wartość tego rejestru). Zapiszmy więc pętlę nieco inaczej z wykorzystaniem własnej wstawki asemblerowej:
procedure Test(i: Integer; const j1, j2: Integer);
var
tablica: array[1..3] of Integer;
a, t: Integer;
begin
t := min(j1, j2);
asm
mov ecx,3
xor eax,eax
lea edx,tablica
@Petla:
mov [edx],eax
add edx,4
dec ecx
jnz @Petla
end;
inc(i, t);
inc(tablica[t], i);
end;
Tak oto teraz zaprezentuje się kod procedury:
5: begin
push ebp
mov ebp,esp
add esp,-$0c
push ebx
push esi
mov esi,eax
6: t := min(j1, j2)
cmp edx,[ebp-$10]
jnl +$04
mov eax,edx
jmp +$03
mov eax,[ebp-$10]
mov ebx,eax
9: mov ecx,3
mov ecx,$00000003
10: xor eax,eax
xor eax,eax
11: lea edx,tablica
lea edx,[esp-$0c]
13: mov [edx],eax
mov [edx],eax
14: add edx,4
add edx,$04
15: dec ecx
dec ecx
16: jnz @Petla
jnz -$08
18: inc(i,t);
add esi,ebx
19: inc(Tablica[t], i)
add [ebp+ebx*4-$10],esi
20: end
pop esi
pop ebx
mov esp,ebp
pop ebp
ret
Jak widać na tym przykładzie zastosowanie kodu asemblera, choć z pozoru pozwoliło zaoszczędzić dwie instrukcje, to w efekcie spowodowało rozrost bloku początkowego i końcowego. Kompilator ewidentnie zaczyna „szukać” wolnych rejestrów. Efekt taki spowodowany jest tym, że po wyjściu z bloku asemblera użyte rejestry nie mają określonej wartości. Dlatego stają się one bezużyteczne do przekazywania danych z kodów wcześniejszych do kodów dalszych. Kompilator radzi sobie poprzez wykorzystanie powolnego stosu.
Z tych powodów użycie asemblera w kodzie powinno być bardzo rozważne i najlepiej poparte analizami wydajnościowymi. Jeśli chcemy w jakiejś prostej procedurze użyć kodu niskopoziomowego, to często lepiej jest zapisać całą procedurę z użyciem tego kodu, niż tylko jej fragmentów (nie stosujemy wówczas słówka begin). Należy stosować taki zapis tylko wówczas, gdy mamy pewność, że będzie on znacznie bardziej optymalny od zapisu przez kompilator, a jednocześnie nie spowoduje zakłócenia efektów działania optymalizatora. Warto pamiętać, że wczesne wersje Delphi przed wejściem w kod asemblera odkładały wszystkie rejestry procesora na stos, a następnie przywracały je po opuszczeniu wstawki. Choć taka operacja pozwalała na niezakłócony przebieg optymalizacyjny reszty programu, to często była zbyteczne i znacząco wydłużała czas potrzebny na rozpoczęcie wykonywania właściwego kodu maszynowego.
Jest jednak jeszcze kilka powodów, dla których warto użyć kodu asemblera. Są to sytuacje, w których pewne zadania są nieosiągalne wprost z poziomu kodu wysokiego poziomu i musiałyby zostać zapisane znacznym nakładem pracy, podczas gdy procesor może zrealizować dane zadanie przy użyciu jednego polecenia (za przykład mogą służyć takie operacje, jak ROL i jej podobne).
Słowo kluczowe with
Tutaj sprawa nie jest taka prosta. Generalnie w większości przypadków zastosowanie tego słowa kluczowego poprawia czytelność kodu, a w pewnych sytuacjach potrafi wyeliminować konieczność deklarowania zmiennych. Niestety wpływ na wydajność bywa różny od sytuacji – może zarówno podnieść jak i obniżyć wydajność aplikacji. Z reguły wzrost wydajności odczujemy, jeśli posłużymy się tym słowem w tych wszystkich przypadkach, w których nie chcemy stosować pomocniczych zmiennych, a część obiektu, do którego się odwołujemy, musi być pobrana przez funkcję (nie jest rekordem, choć i tu bywają odstępstwa, głównie przy rekordach o elementach o rozmiarach nie będących wielkością 1, 2, 4 lub 8).
Jeśli dany fragment kodu używa małej ilości zmiennych i nie są to zmienne pomocnicze, które można zastąpić konstrukcją with, to z pewnością zastosowanie tego słowa kluczowego wpłynie poprawnie na czytelność kodu nie zmieniając jego wydajności. Jednak większość przypadków wymaga indywidualnej analizy, podczas której warto zwrócić uwagę nie tylko na ilość instrukcji, ale także relatywnych odwołań do adresów pamięci.
Jako, że nie potrafię wynaleźć prostego przypadku, gdy zastosowanie with potrafi dać wzrost wydajności, nie zamieszczam przykładu, lecz czekam na propozycje czytelnika.
Właściwy dobór właściwości komponentów
Jak wiadomo, wyświetlenie zawartości jakiegoś komponentu na ekran jest bardzo czasochłonnym zadaniem. Z tego powodu warto przyjrzeć się właściwościom wstawianych komponentów. Pod analizę poddam jeden z najczęściej wykorzystywanych, a mianowicie TLabel.
Komponent ten ma trzy własności, które bezpośrednio wpływają na to, jak komponent będzie rysowany, lecz nie mają wpływu na ostateczny wygląd w większości sytuacji:
- AutoSize – ustawienie tej właściwości powoduje, że rozmiar komponentu dopasowuje się do zawartości tekstu. Jeśli rozmiar jest odpowiednio duży, a kontrolka nie ma reagować na położenie kursora myszy i nie ma innego tła, to różnic nigdy nie zobaczymy. Warto jednak nadmienić, że przewidzieć należy także fakt, że wpływ na rozmiar tekstu w głównej mierze – poza jego treścią – mają ustawienia czcionek u użytkownika.
- ShowAccelChar – włączenie spowoduje, że label stanie się aktywny na skróty klawiaturowe, a litera poprzedzona znakiem ‘&’ zostanie podkreślona i stanie się klawiszem skrótu (w połączeniu z
Alt). W większości przypadków jest to niepotrzebne, a czasem wręcz przeszkadza, gdy chcemy wyświetlać znaki ampersand (&) na etykiecie.
- Transparent – to ustawienie powoduje, że tło pod tekstem staje się przeźroczyste. Jeśli tło jest w tym samym kolorze, co element, na którym umieszczona została etykieta, to ustawienie to nie zmienia niczego wizualnie na formie.
Jak zatem wpływają poszczególne opcje na wydajność wyświetlania? Do zbadania użyłem prostego kodu:
for x := 1 to 70000 do begin
Label1.Caption := Format('%d = %x', [x,x]);
Label1.Repaint;
end;Kod ten wyświetla 70 000 razy różny tekst w postaci liczby od 1 do 70 000 w postaci dziesiętnej oraz szesnastkowej, za każdym razem wymuszając przerysowanie. Wyniki zawarte są w poniższej tabeli. Przedstawia ona wszystkie możliwe kombinacje opisywanych ustawień oraz średni czas wykonywania jednego przebiegu pętli. Dodatkowo w prawej części przedstawione są różnice pomiędzy włączeniem a wyłączeniem danej opcji.
| Transparent | AutoSize | ShowAccelChar | Czas [μs] | Różnice [μs] |
|---|
| ShowAccelChar | AutoSize | Transparent |
|---|
| NIE | NIE | NIE | 157 | | | |
| NIE | NIE | TAK | 159 | 2 | | |
| NIE | TAK | NIE | 258 | | 101 | |
| NIE | TAK | TAK | 260 | 2 | 101 | |
| TAK | NIE | NIE | 186 | | | 29 |
| TAK | NIE | TAK | 188 | 2 | | 29 |
| TAK | TAK | NIE | 300 | | 114 | 42 |
| TAK | TAK | TAK | 303 | 3 | 115 | 43 |
Jak widać z powyższej tabeli różnica pomiędzy skrajnymi przypadkami jest prawie dwukrotna! Najmniejszy wpływ na wydajność ma wyłączenie własności ShowAccelChar – możemy zaoszczędzić ok. 2 μs, czyli maksymalnie 1,3%. Włączenie przeźroczystości to strata już znacznie większa sięgająca 18%. Największy spadek wydajności zaobserwujemy włączając parametr AutoSize – możemy spowolnić w ten sposób wyświetlanie nawet o ponad 60%!
Warto jeszcze zwrócić uwagę na jeden fakt – domyślne ustawienia nie są najwydajniejszymi. Wyłączając automatyczne dopasowanie rozmiaru oraz przypisywanie skrótów zyskamy ok. 40% szybsze przerysowywanie komponentu TLabel. Wystarczy tylko pamiętać, by wcześniej nadać właściwy rozmiar uwzględniając przy tym możliwość wystąpienia większej czcionki u użytkownika.
Blokowanie przerysowania interfejsu komponentów bazujących na typie TStrings
Z poprzednim tematem łączy się kolejny. Najczęstszym niedopatrzeniem programistów jest zadbanie o to, czy komponent ma dokonać aktualizacji swej zawartości, czy też nie. Problem dotyczy wszystkich komponentów wizualnych, których zawartość bezpośrednio bazuje na typie TStrings (a więc i dziedziczący TStringList). Wszystkie obiekty tej klasy posiadają własność BeginUpdate, która określa, czy komponent ma dokonać przerysowania bądź innych działań związanych ze zmianą zawartości string-listy. Polecenia tego używa się przed blokiem programu, który dokonuje modyfikacji listy (dodanie, zmiana treści, usunięcie). To, czy lista jest w trakcie aktualizacji można odczytać poprzez zmienną UpdateCount. Po zakończeniu aktualizacji należy koniecznie wywołać metodę EndUpdate, która wywoła działania związane ze zmianą zawartości string-listy. Oczywiście tego typu zabiegów nie ma sensu wykonywać, jeśli dokonywana jest pojedyncza zmiana (te instrukcje są także wywoływane wewnętrznie przez metody Add, Delete itp.).
Rysowanie w oknach
Kolejny, bardzo często popełniany błąd wiążący się z problemem przerysowywania interfejsu, związany jest bezpośrednio z grafiką. Początkujący programiści próbują ułatwić sobie pracę poprzez rysowanie bezpośrednio na Canvie komponentu TImage. Nie trzeba się wówczas martwić przerysowaniem czy innymi aspektami. Niestety takie rozwiązanie jest bardzo powolne, szczególnie jeśli rysowana jest większa ilość obiektów, lub następuje bardzo częste przerysowanie (np. wirtualny efekt przeciągania jakiejś figury). Dużo szybszym jest rysowanie po obszarze wirtualnej bitmapy (czyli zmiennej typu TBitmap), a następnie, po dokonaniu wszystkich operacji rysowania, których wynik można przedstawić użytkownikowi, przerysowanie jej w całości na komponent wizualny (poleceniem Draw). Warto także pamiętać, że rysowanie dużo szybciej odbywać się będzie po komponencie TPaintBox, gdyż nie wywołuje on automatycznego przerysowania zawartości. Wadą jest to, że należy samemu obsłużyć zdarzenie OnPaint.
|