Pułapki kodu DelphiArtykuł ten poświęcony jest nieoczekiwanym zachowaniom zarówno samego kodu wykonywalnego, jak i debuggera w Delphi w wersji do Delphi 10 Seattle (choć możliwe, że późniejsze wciąż będą działały tak samo). Przedstawię sytuacje, w których teoretycznie poprawny i kompilujący się bez błędów kod działa w sposób nieintuicyjny i niezamierzony, a poszukiwanie przyczyn nieprawidłowości w działaniu może być uciążliwe i trudne.
Na chwilę obecną szczęśliwie jest to krótki tekst, lecz niewykluczone, że w przyszłości rozbuduje się o nowe pułapki, z jakimi uda mi się spotkać i opisać.
Spis treści
Reprezentacja danych w debugerze
Zapewne każdy, kto poddawał swój pod debugowaniu, zetknął się z nieoczekiwaną reprezentacją danych przez debuger, co z kolei mogło powodować szukanie błędów tam, gdzie ich nie ma. Dość powiedzieć, że systemowe narzędzie nie obsługuje choćby danych spod klauzuli with. Pół biedy, gdy żadna dana nam się nie pokaże. Ale jeśli nazwa pola pokrywa się z nazwą pola klasy, w której zastosowano zapis, to prezentowana dana wcale nie będzie pochodzić z tego miejsca, z którego się spodziewamy.

Jednak kwestia związana z prostymi zmiennymi jest jeszcze do ogarnięcia. Jednak debugger wyposażony jest także w tzw. wizualizery wielu standardowych klas, np. TStringList. Jednak, wbrew intuicji, nie stosuje on tych samych parametrów, jak klasa, której dane chcemy podejrzeć. To może być źródłem problemów, gdy w taki sposób próbujemy sprawdzić zawartość zmiennych. Jednak bez obaw - kod działa poprawnie!
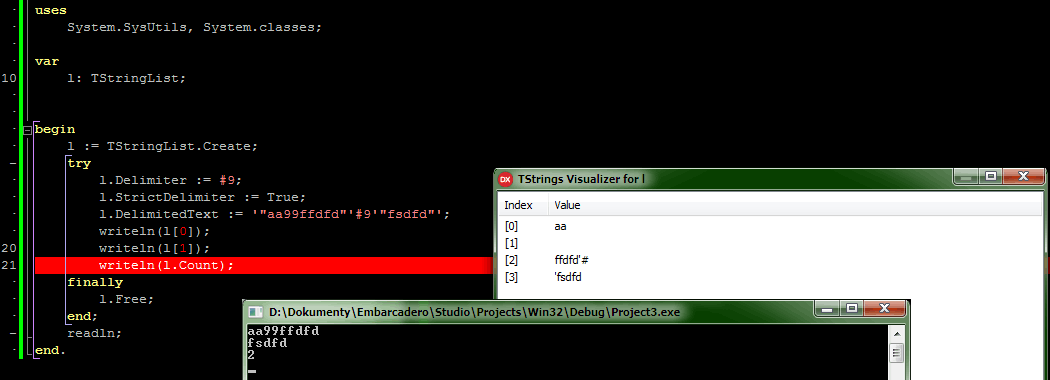
Niekonsekwencja(?) funkcji inline
Funkcje inline w Delphi są świetnym narzędziem do skracania kodu bez szkody w wydajności działania. Są bardziej jak makra, gdzie wywołanie takiej funkcji podczas kompilacji zostanie zastąpione jej ciałem. Więcej na ich temat można znaleźć w poradzie Optymalny, wysokowydajny kod w Delphi.
Jedną z bardziej popularnych jest na pewno funkcja IfThen z modułów System.Math (dla liczb) i System.StrUtils (dla ciagów tekstowych). Przyjrzyjmy się przykładowej:
function IfThen(AValue: Boolean; const ATrue: Integer; const AFalse: Integer = 0): Integer; overload; inline;
begin
if AValue then
Result := ATrue
else
Result := AFalse;
end;
Napiszmy teraz prosty program korzystający z takiej funkcji:
var
o: TControl;
r: Integer;
begin
o := nil;
r := IfThen(o = nil, 0, 1);
writeln(r);
end;
Gdyby funkcja nie była typu inline (lub stosowanie tej właściwości zostało wyłączone w opcjach kompilatora) skompilowany kod w miejscu jej użycia wyglądałby następująco:
r := IfThen(o = nil, 0, 1);
cmp dword ptr [ebp-$04],$00
setz al
mov ecx,$00000001
xor edx,edx
call IfThen
mov [ebp-$08],eax
Widać tu inicjację rejestrów w celu przekazania do wywołania funkcji IfThen oraz jej wywołanie (call).
Jednakże dzięki temu, że funkcja jest zdefiniowana jako inline, wówczas generowany kod jest następujący:
r := IfThen(o = nil, 0, 1);
cmp dword ptr [ebp-$04],$00
jnz +$09
xor eax,eax
mov [ebp-$0c],eax
jmp +$09
mov [ebp-$0c],$00000001
mov eax,[ebp-$0c]
mov [ebp-$08],eax
Nie ma tutaj żadnego wywoływania funkcji, a kod jest praktycznie identyczny, jak gdyby zapisać go w następujący sposób:
if (o = nil) then
r := 0
else
r := 1;
Prawda, że pierwszy zapis jest wygodniejszy, czytelniejszy i znacznie skraca kod źródłowy? A jednocześnie nic nie straciliśmy na wydajności (nadmieniam, że wywołania funkcji są jednymi z bardziej czasochłonnych operacji, gdyż wiąże się to z kilkoma poleceniami więcej w ramach wejścia i wyjścia funkcji; więcej na ten temat można znaleźć w przytoczonej już wcześniej poradzie).
Gdzie zatem czai się niebezpieczeństwo? Zmieńmy tylko zwracaną wartość tak, aby w przypadku istnienia obiektu, była zwracana wartość pola Tag, a jeśli obiekt nie jest utworzony - 0:
r := IfThen(o = nil, 0, o.Tag);
Zgodnie z logiką i rozwinięciem funkcji inline, kod jest poprawny. Jednak, gdy podejrzymy skompilowaną wersję, zobaczymy coś takiego:
r := IfThen(o = nil, 0, o.Tag);
mov eax,[ebp-$04]
mov eax,[eax+$0c]
mov [ebp-$0c],eax
cmp dword ptr [ebp-$04],$00
jnz $005c6cdd
xor eax,eax
mov [ebp-$10],eax
jmp $005c6ce3
mov eax,[ebp-$0c]
mov [ebp-$10],eax
mov eax,[ebp-$10]
mov [ebp-$08],eax
Bardziej doświadczeni dostrzegą tu jeden istotny szczegół: jeszcze przed wykonaniem porównania następuje odwołanie do pola Tag, a przecież obiekt nie istnieje. I tak, taki kod skończy się błędem dostępu! Nie jest więc w żaden sposób równoważny kodowi:
if (o = nil) then
r := 0
else
r := o.Tag;
Niestety, w takim przypadku nie możemy skorzystać z dobrodziejstw funkcji inline. Skąd takie zachowanie? Choć wydawało się, że funkcje inline są czymś podobnym do makr, gdzie w miejsce ich wywołania kompilator podstawia kod, wcale tak nie jest! Związane jest to z faktem, że w przypadku zwykłych funkcji wszystkie parametry muszą być wyliczone wcześniej przed przekazaniem. A co, gdyby Tag był właściwością, w której getter nie byłby prostym pobraniem wartości pola, lecz funkcją dodatkowo zmieniającą cokolwiek w klasie? Stąd właśnie wczesne wywołanie gettera. Kompilator broni się przed różnym działaniem w zależności od ustawień. I bardzo dobrze, że tak się dzieje, bo dzięki temu program działa niezmiennie niezależnie od parametrów. Ale trzeba pamiętać, że funkcje inline nie są do końca makrami, lecz hybrydą funkcji i makra, a największą wydajność (a w tym przypadku i poprawność działania) zapewni tylko własne rozwinięcie kodu bez korzystania z dobrodziejstw modyfikatora inline. Warto przyjąć, że funkcje inline sprawdzą się tak samo, jak ich rozwinięcie, jeśli przekazywać będziemy im stałe lub proste zmienne. W przypadku jakichkolwiek wartości, które muszą być pobrane/wyliczone (czyli własności klas, ich metody, funkcje), a nie zostaną w każdym przypadku użyte wewnątrz funkcji (jak jest to w przypadku IfThen) lepiej zastanowić się, czy warto ją zastosować.
Procedury anonimowe i wyciek pamięci
W nowszych wersjach Delphi wreszcie istnieją procedury lub funkcje anonimowe. Niesamowicie upraszczają pisanie kodu, jednocześnie często pozwalając na rezygnację z funkcji zagnieżdżonych (których użycie od zawsze wiązało się z drastycznym spadkiem wydajności podczas wywołania takiej funkcji) lub niepotrzebnej deklaracji na poziomie klasy. Ot, choćby przypadek sortowania list przy użyciu własnej metody porównywania. Poniżej przykład funkcji mieszającej:
var
o: TList<Integer>;
i: Integer;
begin
o := TList<Integer>.Create();
try
o.AddRange([1, 2, 3, 4, 5]);
//mieszaj:
o.Sort(TComparer<Integer>.Construct(function(const Left, Right: Integer): Integer
begin
Result := Random(3) - 1;
end));
for i in o do
writeln(i);
finally
o.Free;
end;
end;
Wszystko fajnie i ładnie. Co jednak się stanie, jeśli jedną funkcję anonimową zechcemy użyć w innej?
type
TLos = reference to function: Integer;
var
o: TList<Integer>;
i: Integer;
Los: TLos;
begin
o := TList<Integer>.Create();
try
o.AddRange([1, 2, 3, 4, 5]);
//mieszaj:
Los := function: Integer
begin
Result := Random(3) - 1;
end;
o.Sort(TComparer<Integer>.Construct(function(const Left, Right: Integer): Integer
begin
Result := Los;
end));
for i in o do
writeln(i);
finally
o.Free;
end;
end;
Wcześniej zdefiniowaliśmy anonimową funkcję Los, której użyliśmy w kolejnej anonimowej funkcji będącej parametrem konstruktora klasy TComparer<T>. Wszystko wydaje się działać, lecz monitor wycieków pamięci (można do włączyć przez określenie zmiennej ReportMemoryLeaksOnShutdown := True) pokaże raport:
Unexpected Memory Leak
An unexpected memory leak has occurred. The unexpected small block leaks are:
21 - 28 bytes: test$0$ActRec x 1
Ten wyciek właśnie pochodzi z niezwolnionej funkcji anonimowej. Jak sobie z tym poradzić? A no w takim przypadku po każdym użyciu, gdy funkcja anonimowa przestaje być potrzebna, należy wyzerować zmienną z nią związaną. Z jakiegoś powodu kompilator Delphi nie potrafi zapanować sam nad tym zagadnieniem.
type
TLos = reference to function: Integer;
var
o: TList<Integer>;
i: Integer;
Los: TLos;
begin
o := TList<Integer>.Create();
try
o.AddRange([1, 2, 3, 4, 5]);
//mieszaj:
Los := function: Integer
begin
Result := Random(3) - 1;
end;
o.Sort(TComparer<Integer>.Construct(function(const Left, Right: Integer): Integer
begin
Result := Los;
end));
Los := nil;
for i in o do
writeln(i);
finally
o.Free;
end;
end;
Teraz wszystko będzie ok. Dlaczego nie umieszczono przypisania nil zaraz po przypisaniu do Result wewnątrz funkcji sortującej? Wszak tam jest jej ostatnie użycie. Odpowiedź jest prosta: Ponieważ funkcja porównująca wywoływana jest kilkukrotnie. Należy zawsze głęboko zastanowić się, w którym momencie takie zwolnienie wywołać, szczególnie pisząc aplikacje wielowątkowe. Niech podpowiedzią będzie fragment kodu:
if (chbAnyc.Checked) then
TTask.Run( procedure
begin
TThread.Synchronize(nil, proc);
proc := nil;
end)
else if (Sender is TThread) then
begin
TThread(Sender).Synchronize(TThread(Sender), proc);
proc := nil;
end
else
begin
proc();
proc := nil;
end;
Anonimowa procedura proc jest jedna, ale w zależności od sytuacji może być użyta w osobnym zadaniu, w ramach synchronizacji wątku lub bezpośrednio w wątku, który ją wywołał. Kod jest krótki, ale trzeba pamiętać o wyzerowaniu w momencie, gdy przestaje być użyteczna. Nie można w powyższym przykładzie zrobić jednego przypisania nil na koniec, gdyż w przypadku zadania (TTask) nie mamy kontroli nad tym, kiedy zostanie ono wykonane i zakończone.
Zdradziecki TListBoxStrings
Zapewne wielu wykorzystywało własność Object typów dziedziczących po TStrings do przechowywania nie obiektów, a prostych wartości liczbowych. Wszak gdy potrzebujemy przechować tylko liczbę typu NativeInt (czyli Integer w 32-bitowych aplikacjach) wpisanie wprost jej wartości jest najszybsze zarówno pod względem tworzenia kodu jak i wydajności jego działania.
Przeanalizujmy prosty kod dodający pozycje do komponentu TComboBox:
for i := -5 to 5 do
ComboBox1.Items.AddObject('10^' + IntToStr(i), Pointer(i));
Następnie w zdarzeniu OnSelect można wykorzystać to w następujący sposób:
SpinEdit2.Value := Round(SpinEdit1.Value * IntPower(10, Integer(ComboBox1.Items.Objects[ComboBox1.ItemIndex])));
Widać, że wybór pozycji z listy spowoduje przemnożenie liczby w jednym komponencie przez 10 podniesione do wybranej potęgi i zapisze w drugim. Wszystko fajnie, ładnie, cieszymy się bardzo prostym, krótkim i szybkim kodem, na dodatek w prosty sposób dającym zmieniać zakres potęg... Aż do wyboru wartości -1. W tym momencie dostaniemy komunikat List index out of bounds (4). Ale jak to? Przecież elementów jest 11! Jak można przekroczyć zakres? To samo stanie się, jeśli np. spróbujemy znaleźć pozycję wartości przy użyciu IndexOfObject. Co więcej, przecież takie same przypisania np. w klasach TList lub TStringList działają nie powodując problemów.
Odpowiedzią jest typ TListBoxStrings używany przez sporą część komponentów. Choć formalnie dziedziczy on po TStrings (i takim typem przedstawiają się klasy, lecz w rzeczywistości jest to właśnie wspomniany wcześniej typ), to jednak wprowadza inną obsługę wartości. A tam znajduje się kod, dla którego wartość -1 (a ściślej: $FFFFFFFF - w przypadku kompilacji 32-bitowych) jest wartością szczególną, która właśnie zwraca taki wyjątek (zainteresowanym polecam przyjrzeć się definicji metody TListBoxStrings.Get w System.StdCtrls).
Niestety, niespodzianka może zaskoczyć z czasem, skutecznie unikając testów. Co można zrobić? Zastosować styl lbVirtual lub lbVirtualOwnerDraw i zdarzenie OnData. Inny sposób polega na tworzeniu prawdziwych obiektów, które zostaną przypisane (adres $FFFFFFFF nigdy nie będzie miał miejsca), lecz trzeba pamiętać o ich późniejszym zwolnieniu. Trzecia opcja polega na posłużeniu się towarzyszącymi tablicami, czyli osobną zmienną, którą niestety trzeba utrzymywać wraz ze zmianami w liście Items komponentów - w przypadku używania np. sortowania staje się to jednak kłopotliwe. |