Czysty i czytelny kod w DelphiSpis treści
Wstęp
Pisząc na bieżąco kod można łatwo zaniedbać kwestię jego czytelności i przejrzystości. Szczególnie początkujący programiści nie wychodzą z czynieniem kodu czytelnym ponadto, w czym wspiera ich edytor. Czasem ich kod w ogóle fiest nieprzejrzysty, przez co np. próbując uzyskać pomoc i podając jego fragment, w ogóle jej nie otrzymują. Czytelność kodu nabiera znaczenia także po pewnym czasie, gdy trzeba do niego wrócić, by coś zmienić, dodać, poprawić. W pracy programisty zdecydowaną większość czasu spędza się nie na tworzeniu, lecz na czytaniu kodu właśnie, a praca zespołowa tylko pogłębia tą proporcję.
Warto zatem od początku nabierać właściwych nawyków w pisaniu kodu. Niniejszy poradnik adresowany jest głównie do programistów języka Pascal ze szczególnym naciskiem na środowisko Delphi, lecz myślę, iż także używający innych języków mogą z tego wynieść wiele cennych wskazówek. Warto przy tym nadmienić, że wszelkie zabiegi "upiększające" kod Pascala - poza nielicznymi wyjątkami - nie mają żadnego przełożenia na funkcjonalność (jak może mieć miejsce w przypadku np. JavaScript, który potrafi automatycznie dodawać średniki na końcu linii, jeśli sądzi, że ich brakuje).
Od wersji 2010 środowisk RAD firmy Embarcadero pojawiło się funkcjonalne narzędzie wbudowane, które pozwala na formatowanie kodu - Source Code Formatting. Bardzo dużo opcji opatrzonych jest przykładem działania, zatem nie będę w dalszej części kodu odwoływał się już do ustawień tego narzędzia, lecz na koniec każdego z działów załączę zrzut ekranu z ustawieniami, które odpowiadają zaznaczonym w tekście moim preferencjom. Warto jednak zwrócić uwagę, że zastosowanie tego narzędzia ma sens do starych, źle sformatowanych kodów, lub w kontekście zaznaczonego fragmentu. Nie wszystkie elementy czytelnego kodu zostaną jednak spełnione po użyciu narzędzia automatycznego formatowania - są przypadki, w których wprowadzi ono więcej bałaganu niż porządku w kod.
Wcięcia i linie
Znaki nowej linii oraz wcięcia to najistotniejsze elementy poprawiające czytelność kodu. Teoretycznie w pełni działający kod może wyglądać np. tak:
program myapp; {$APPTYPE CONSOLE} uses system.sysutils;procedure writehello;begin write('Hello!');end; var i:integer;begin for i:=0 to 2 do begin if i>0 then write(i);writehello;writeln;end;end.
Zapisany w jednej linijce jest kompletnie nieczytelny, choć mniej więcej właśnie w ten sposób widzi go kompilator. Pierwsza zasada mówi, że w jednej linii powinno znajdować się jedno funkcjonalne polecenie. Najczęściej oznacza to, że każda linia kończy się średnikiem (wyjątek stanowią parametry procedur i funkcji oddzielane średnikami, dookreślenia funkcji lub metod, czyli słowa kluczowe takie, jak stdcall, abstract, virtual, reintroduce, overload, external i im podobne). Jednak czasem jedno polecenie może składać się z wielu linii. Nie należy także obawiać się wstawiania pustych linii, które mogą oddzielać składowe programu, jak i pewne logiczne bloki w ramach jednej procedury czy funkcji.
Drugim aspektem są wcięcia, bez których kod (szczególnie większy niż kilka linijek) staje się niemożliwy do odczytania. Na początek należy sobie zdać sprawę, że istnieją dwie szkoły robienia wcięć - za pomocą znaku spacji lub tabulacji. Domyślnie większość edytorów wykorzystuje pierwszą metodę wstawiając w ramach wcięcia dwie lub cztery spacje. Choć zarówno wykorzystanie spacji jak i tabulacji ma swoich zwolenników jak i przeciwników, to każda z tych metod obarczona jest pewnymi mankamentami:
Spacje wymagają określonej liczby powtórzeń klawisza, co wymaga pewnej dyscypliny. Jednak kod formatowany przy ich użyciu będzie zawsze wyglądał jednakowo u każdego użytkownika, który będzie go otwierał w dowolnym edytorze.
Tabulacje są prostsze w użyciu, a co więcej, każda osoba może w edytorze określić sobie, jak głęboka ma być tabulacja, czyli co ile znaków ma następować. Dzięki temu bez jakiejkolwiek ingerencji w kod, ten będzie z wcięciami odpowiadał preferencjom czytającego. Ponadto pliki kodu źródłowego są mniejsze. Minusem tej metody z pewnością jest zaburzenie formatowania po przeniesieniu kodu do edytorów wizualnych, w których tabulacje umieszczane są na określonych pozycjach wyrażonych w centymetrach, a nie w znakach (np. Word).
Osobiście, zdecydowanie preferuję użycie znaku tabulatora. Aby efektywnie go wykorzystywać warto w środowisku Delphi zmienić ustawienia edytora. Wchodzimy zatem do ustawień Tools / Options..., następnie przechodzimy do gałęzi Editor Options / Soruce Options i zmieniamy trzy ustawienia: Use tab charakter pozwoli na użycie znaku tabulacji; wyłączenie Cursor through tabs uniemożliwi wchodzenie kursorem w "środek" tabulacji (dzięki czemu nie zepsujemy jej wpisując znak); wybranie Optimal fill sprawi, że każdy otwarty kod będzie wypełniany tabulatorami w miejsce wiodących spacji tyle razy, ile będzie to możliwe (czyli np. 4 spacje zostaną zastąpione znakiem tabulatora). Dwie opcje: Block indent oraz Tab stops definiują odpowiednio ilu znakowe ma być wcięcie, oraz co ile znaków ma przeskakiwać spacja. W przypadku używania tabulatora do wykonywania wcięć te wartości muszą być sobie równe!

W tym miejscu drobna uwaga. Właśnie ze względu niedogodności wskazanej dla używania tabulacji wszystkie kody przedstawione na tej stronie używają znaku spacji do definiowania wcięć.
Kiedy i jak stosować wcięcia? Przede wszystkim zawsze do zawartości bloków kodu znajdujących się pomiędzy słowami begin..end. Stosujemy je także pod poleceniami warunkowymi czy pętlami, które składają się z pojedynczej linijki kodu wykonywanej w ramach warunku lub pętli. Także cała treść pętli repeat..until powinna być wcięta, jak i warunkowa instrukcja case..end. Ponadto warto je stosować także pod sekcjami użycia (uses), typów (type), stałych (const), zmiennych (var), funkcji zawartych wewnątrz innych. Nie ma natomiast potrzeby używania ich w ciałach klas w odniesieniu do modyfikatorów widoczności (ale już pod nimi jak najbardziej) czy do wykonywania wcięć części interfejsowej (interface) czy implementacyjnej (implementation), gdyż występują one raz w kodzie i nie posiadają formalnie znaczników kończących.
Osobnym zagadnieniem jest samo położenie słowa kluczowego begin, a wraz z nim idąca możliwość wcięcia samego bloku. Spotkać można trzy szkoły:
- Wcięcie sekcji oraz zawartości:
if a then
begin
doSomething();
end;
- Pozostawienie
begin na tym samym poziomie:
if a then
begin
doSomething();
end;
- Nieprzenoszenie słowa kluczowego
begin do nowej linii:
if a then begin
doSomething();
end;
Osobiście preferuję trzecie podejście (z pewnym odstępstwem, o czym w dalszej części), choć zdecydowana większość programistów wybiera drugie rozwiązanie, które ma dwie zalety w przeciwieństwie do mojego: 1. zawsze widać, czy blok jest poprawnie rozpoczęty; 2. weryfikacja wizualna kodu nie opiera się tylko o wcięcia, które mogą wprowadzić w błąd. Natomiast wadą jest pewne zaburzenie zasady wcinania kodu pod instrukcjami warunkowy. Eliminuje go co prawda pierwszy model, lecz wprowadza on bardzo dużą liczbę wcięć co sprawia, że szerokość kodu rośnie ponad miarę.
Jeśli już wspomnieliśmy o wcięciach wprowadzających w błąd, trzeba podkreślić, że niewłaściwe użycie wcięć jest jeszcze gorsze, niż ich nieużywanie. Można bowiem łatwo o następującą pułapkę:
if a then
doA;
doB;
doC;
Jeśli ktoś spojrzy na ten kod może ulec złudzeniu, że instrukcje doA i doB wykonają się pod warunkiem a. Tymczasem tylko funkcja doA jest objęta warunkowym wykonaniem.
Zbliżonym zagadnieniem do przejścia do nowej linii przed słowem begin jest postępowanie przy instrukcji else. Co do wcięcia nie ulega wątpliwości, że powinna ona znajdować się w tej samej kolumnie, co instrukcja if (lub case). Natomiast jeśli blok podwarunkowy składa się z bloku begin..end, który sam w sobie nie jest wcinany, to osobiście preferuję zajmujący nieco mniej linijek zapis w jednej linijce sekwencji end else begin, chyba że bezpośrednio za else znajduje się kolejna instrukcja warunkowa.
Przekształćmy zatem przykładowy kod z początku rozdziału z zastosowaniem wcięć i nowych (także nie bojąc się pustych) linii:
program MyApp;
{$APPTYPE CONSOLE}
uses
System.SysUtils;
procedure WriteHello;
begin
write('Hello!');
end;
var
i: Integer;
begin
for i := 0 to 10 do begin
if i > 0 then
write(i);
WriteHello;
WriteLn;
end;
end.
Jak widać na przykładzie, za pomocą podwójnych pustych linii wyróżniono 3 części - deklaracji, procedur i główną. Wprowadzono także nowe linie i wcięcia tam, gdzie teoretycznie nie było takiej potrzeby - po instrukcji if..then oraz po sekcjach załączonych plików czy zmiennych - uses oraz var. Kod natychmiast stał się dużo bardziej przejrzystym.
Temat wcięć jednak nie jest jeszcze wyczerpany. Zachodzą czasem okoliczności, w których np. warunki instrukcji if są bardzo rozbudowane. W takiej sytuacji nie ma co liczyć na formatera kodu, bo może on przynieść więcej szkód niż pożytku. Warto w takiej sytuacji nie bać się używać zarówno wcięć jak i nowych linii w ramach jednej instrukcji. Podobnie ma się sprawa w przypadku, gdy wykonywana funkcja przyjmuje jako argumenty kolejne funkcje z argumentami. Zapis w jednej linii z pewnością nie będzie czytelny. Ostatni przypadek to zapis dłuższych ciągów tekstowych. Jeśli posiadają one znak nowej linii, to warto wykorzystać go także do złamania linii w kodzie. Poniższy kod obrazuje wszystkie wymienione w tym akapicie przypadki:
if ( ((x = left) or (x = right)) and
((y >= top) and (y <= bottom))
) or
( ((y = top) or (y = bottom)) and
((x >= left) and (x <= right))
) then
begin
Application.MessageBox( Pchar( Format('Punkt (%d,%d) znajduje się na obwodzie prostokąta.'#13 +
'Zadanie wykonane poprawnie!',
[x, y])
),
'Komunikat',
MB_ICONINFORMATION);
end;
Bardzo wyraźnie warunek został podzielony na część sprawdzania położenia punktu na lewym i prawym boku prostokąta lub na podstawie górnej i dolnej. Dodatkowo w każdym z tych testów oddzielono linię sprawdzającą współrzędną leżącą na linii od sprawdzania drugiej współrzędnej. Funkcja wyświetlająca komunikat składa się z rzutowania wyniku funkcji format, która przyjmuje dwulinijkowy tekst oraz, w drugim parametrze, tablicę wartości. Tekst został jawnie podzielony w kodzie na dwie linijki, a parametry funkcji format znalazły się w kolejnej. Zamknięcie rzutowania PChar znalazło się pod nawiasem otwierającym, natomiast pozostałe parametry metody MessageBox są na równi z początkiem pierwszego parametru (PChar). Pragnę zauważyć jeszcze jedną rzecz - w tym akurat przypadku słowo begin wyjątkowo (jak dla przyjętego przeze mnie stylu kodu) znalazło się w nowej linii. Gdyby pozostawić je za słowem kluczowym then, wówczas uzyskamy efekt zlania się warunków z instrukcją podwarunkową. Stąd wyjątek od mojej reguły.
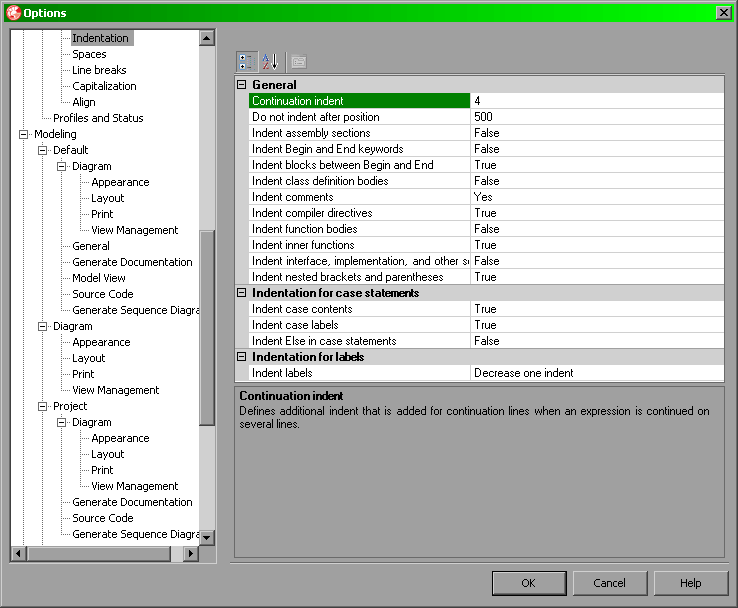
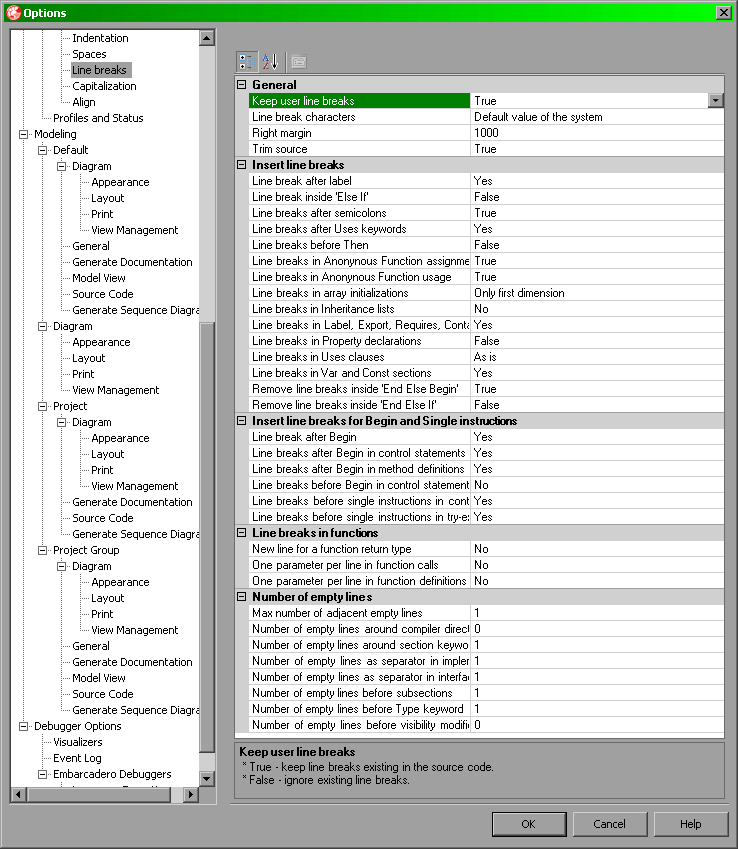
Za ustawienia wcięć odpowiada sekcja ustawień Indentation zaś za znaki nowej linii sekcja Line breaks.
Wyrównania i odstępy
Tematem blisko spokrewnionym z wcięciami są wyrównania. Polega to na tworzeniu wielokolumnowego kodu; np. przy definicji stałych i zmiennych w jednej kolumnie znajdują się nazwy, zaś w drugiej - ich wartości/typy. Przy przypisaniach występujących w kolejnych liniach wyrównania mogą być prowadzone względem znaku przypisania.
const
PI = 3.14;
EULER = 2.72;
var
a : Real;
str : String;
myObj : TObject;
begin
a := PI * EULER;
str := 'Tekst';
myObj := Self;
end;Przy tym wyrównania mogą być prowadzone wg znaków przypisania/określenia (jak w przykładzie powyżej), ale też wg wartości/typów - wówczas znaki równości, dwukropka lub operatory przypisania nie znajdują się w jednej kolumnie, lecz są przy operandach lewej strony.
Osobiście rzadko stosuję wyrównania w sekcjach typów, stałych czy zmiennych, lecz często stosuję je w przypadku przypisań, szczególnie np. jeśli określane są kolejne pola obiektu.
Drugim zagadnieniem jest stosowanie odstępów. Podobnie jak w języku pisanym, po każdym przecinku lub kropce stosuje się odstęp, tak podobne zasady panują podczas pisania kodu. Przykład poniższego kodu ukazuje małą przejrzystość w przypadku braku stosowania odstępów. Choć częściowo kolorowanie składni może ratować, to jednak kod wciąż nie jest łatwy do czytania.
function Calc(const a:integer;b:real):boolean;
const
r:array[0..2]of real=(1.1,2.3,3.1);
var
c:integer;
begin
result:=0;
for c:=0 to 2 do
if(a=0)or(b=0)or(result=0)then
result:=1
else
result:=result+a*-b*r[c];
end;
Warto zwrócić tu uwagę na kilka aspektów stosowania wcięć:
- przy operatorze określania typu - dwukropku - osobiście stosuję wyłącznie za dwukropkiem (jak w tekście pisanym)
- przy średnikach oddzielających parametry funkcji - moje preferencje są identyczne, jak dla dwukropka.
- przy przecinkach oddzielających elementy tablic lub parametry wywoływanej funkcji - tu także preferuję stosowanie pojedynczego odstępu wyłącznie po przecinku.
- przy operatorach przypisania oraz arytmetycznych i logicznych - tutaj najlepiej oddzielać odstępem zarówno przed jak i za operatorem.
- przy nawiasach - osobiście nie widzę potrzeby tworzenia dodatkowych odstępów wewnątrz jak i na zewnątrz nawiasów z wyjątkiem oddzielania nawiasów od instrukcji niebędących nazwami funkcji lub odwołaniem do elementu tablicy.
- przy operatorze zakresu (
..) - osobiście nie stosuję, choć niestety formater Delphi nie pozwala na zastosowanie osobnej reguły do tego operatora.
Stosując odstępy zgodnie z opisanymi powyżej sugestiami otrzymujemy znacznie bardziej przejrzysty kod:
function Calc(const a: integer; b: real): boolean;
const
r: array [0..2] of real = (1.1, 2.3, 3.1);
var
c: integer;
begin
result := 0;
for c := 0 to 2 do
if (a = 0) or (b = 0) or (result = 0) then
result := 1
else
result := result + a * -b * r[c];
end;
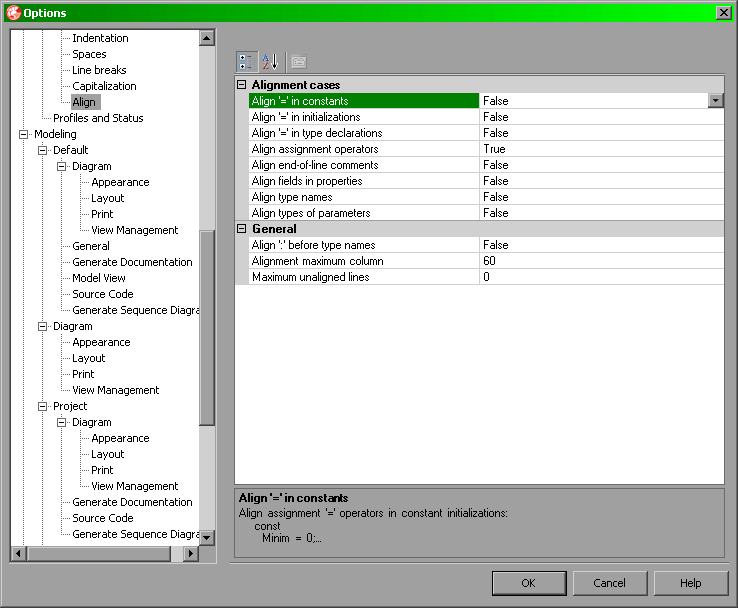
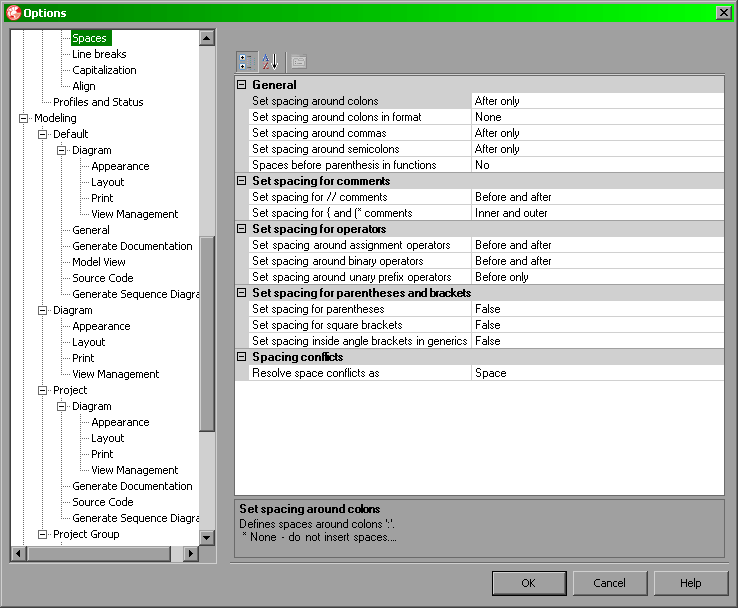
Kwestię wyrównań definiuje się w sekcji Align, natomiast odstępów w sekcji Spaces.
Nazewnictwo i wielkość liter
Zacznijmy od tematu wielkości liter, który częściowo mieści się jeszcze w ramach ustawień formatera kodu. Choć jak wiadomo używając języka Pascal zwolnionym się jest z wymogu przestrzegania wielkości liter i nie ma ona najmniejszego znaczenia dla kompilatora, to jednak czy wyobraża sobie ktoś kod zapisany np. tak, jak poniżej?
FUNCTION GETHELLO(CONST PARAM: BYTE): STRING;
CONST
DEF_MASK = $0F;
VAR
TEST: BOOLEAN;
BEGIN
CASE PARAM OF
0: TEST := TRUE;
1: TEST := FALSE;
ELSE
TEST := (PARAM AND DEF_MASK) > 0;
END;
IF TEST THEN
RESULT := 'Hello!'
ELSE
RESULT := 'Hi!';
END;
Choć taki kod spełnia wszystkie wymienione wczesniej warunki kodu, to jednak wcale on czytelnym nie jest.
Na początek weźmy wszelkie słowa kluczowe (ang. reserved words), czyli z reguły to, co jest domyślnie zaznaczone pogrubieniem przez funkcję kolorowania składni. Najczęściej spotykaną (i preferowaną przeze mnie) konwencją jest zapis tych słów przy użyciu małych liter. Rzadziej spotyka się rozpoczynanie z wielkiej liter.
Drugi element to wszystkie słowa niekluczowe (jak np. typy zmiennych). Tu także postępuje się najczęściej identycznie, jak w poprzednim przypadku.
Specyficznym elementem dla Delphi są wewnątrzkodowe dyrektywy kompilatora (rozpoczynające się znakiem klamrowym i dolara - {$). Warto wyróżnić je od komentarzy stosując w nich właśnie wielkie litery.
Formater kodu w Delphi dostarcza jeszcze jedną regułę dla liczb zapisywanych w systemie szesnastkowym lub naukowym. Tutaj dla mnie osobiście także zastosowanie wielkich liter jest bardziej czytelne.
Kolejna kwestia znajduje się na styku nazewnictwa i wielkości liter. Chodzi tu głównie o nazwy zmiennych, stałych, funkcji składające się z więcej niż jednego wyrazu. Wyróżnić tu można dwie szkoły: tzw. stylu wielbłądziego oraz używania znaku podkreślenia. Osobiście zdecydowanie preferuję styl wielbłądzi, w którym cały zlepek zapisywany jest razem, lecz każdy człon zaczyna się z wielkiej litery. Alternatywą jest rozdzielanie wyrazów znakiem podkreślenia (_). Czasami programiści wykorzystują np. pierwszy styl do zmiennych a drugi do nazw funkcji lub odwrotnie. Ja akurat preferuję styl wielbłądzi zarówno przy nazwach funkcji, jak i zmiennych. Natomiast z tych reguł - wg moich preferencji - wyłamują się nazwy stałych, które zapisuję wielkimi literami (podobnie, jak ma to miejsce w kodach PHP). Dzięki takiemu zapisowi natychmiast widać, że w kodzie ma się do czynienia ze stałą, która definiowana jest na etapie kompilacji kodu, i ewentualna zmiana wartości winna być szukana właśnie w sekcji stałych.
W Delphi za ustawienia formatera związane z wielkością liter odpowiada sekcja Capitalization.
Twórcy środowiska Delphi przyjęli wiele konwencji nazewnictwa, z którymi spotykamy się cały czas, być może nawet nie zdając sobie z tego sprawy. Jak wiadomo, do czynienia mamy z różnymi strukturami danych, takimi jak rekordy, typy, określone ich pola, właściwości i metody. Aby rozróżnić przykładowo typ od zmiennej czy nazwy funkcji, ich nazwę zaczyna się wielką literą T (TObject, TFont). W klasach wewnętrzne pola (czyli zmienne w klasie) rozpoczynają się wielką literą F. Do ustawienia lub czytania własności z kolei wykorzystuje się metody, których nazwa składa się ze słowa Set lub Get i nazwy własności.
type
TMyClass = class
private
FColor: TColor;
function SetVal(const aVal: Integer);
procedure GetVal: Integer;
public
property Val: Integer read GetVal write SetVal;
end;
Kolejną konwencją jest określone nazywanie typów wyliczeniowych - ich nazwy tworzy się dodając przedrostek wskazujący na dany typ wyliczeniowy. Widać to np. na znanym zapewnie typie TWindowState:
type TWindowState = (wsNormal, wsMinimized, wsMaximized)
Na bazie takich powstało wiele mniej formalnych konwencji, które stosują programiści. Pierwszą z nich jest odróżnienie parametrów funkcji dodając na ich początku literę a (analogicznie, jak litera T dla typów). Dla stałych analogicznie dodać można literę c. W przypadku zmiennych pojawia się albo litera v albo litera lub litery odpowiadające typowi zmiennej (np.: sText: string). Z kolei rekordy wyróżnia się literą R, czasem też całym przedrostkiem Rec.
Warto ten schemat stosować także do nazywania komponentów. I tak np. komponent typu TLabel nazwany przez środowisko domyślnie Label1 lepiej przemianować na lblNaglowek niż tylko Naglowek. Po co aż tak daleko posunięta integracja w nazwy, ktoś zapyta? A mianowicie nie tylko jasno i wyraźnie wskazuje to na typ użytego komponentu (a więc łatwo można się domyślić jego metod czy własności, a także sprawdzić poprawność przekazywania do funkcji), ale niesamowicie upraszcza pisanie kodu przy współpracy z "podpowiadacza" kodu. Jeśli bowiem pozostawimy nazwy w postaci prostej, to choć czytelne, to będziemy za chwilę się zastanawiać, czy nasza etykieta na górze okna nazywa się Naglowek czy może Header. Natomiast prawie zawsze wiemy, że będzie nam chodzić o etykietę TLabel. W przypadku stosowania prefiksów wystarczy wpisać w kod lbl, a środowisko samo podpowie nam nazwę prezentując niechybnie wszystkie labele na formatce (o ile do wszystkich zastosujemy tą konwencję).
Stosując się do wskazówek zawartych w tej części tekstu kod z jej początku przybierze znacznie przyjaźniejszą formę:
function WriteHello(const aParam: byte): string;
const
DEF_MASK = $0F;
var
bTest: boolean;
begin
case aParam of
0: bTest := true;
1: bTest := false;
else
bTest := (aParam and DEF_MASK) > 0;
end;
if bTest then
Result := 'Hello!'
else
Result := 'Hi!';
end;
Komentarze
Z pewnością niejeden początkujący programista (bo mam nadzieję, że nie zaawansowany) usłyszał "dodawaj komentarze!". Komentarze służyć mogą wielu celom. Podstawowy to opisywanie znaczenia danej części kodu. Dzięki temu w przyszłości łatwo będzie sprawdzić, co dana część kodu tak naprawdę wykonuje. Pomaga w tym aż kilka możliwości zapisu komentarza, od liniowego (zaczynającego się znakami // a kończącego nową linią), po blokowe: klamrowe ({}) oraz ograniczonego znakami (* *). Warto stosować komentarze klamrowe jako mniejsze bloki lub wręcz wtrącenia w środek linii kodu, zaś drugą konwencję do wyłączania części kodu (gdyż oba rodzaje komentarzy blokowych są niezależne).
Drugie zastosowanie to tworzenie prostych dokumentacji funkcji, gdzie w komentarzu opisujemy sens funkcji, znaczenie parametrów, oraz zwracane wartości. Warto w tym miejscu nadmienić, że nowe wersje środowiska z Embarcadero posiadają preinstalowane narzędzie dokumentacji kodu o nazwie Documentation Insight. Jest to świetne narzędzie realizujące omawiany cel i w pełni współpracujące ze środowiskiem.
Trzecie zastosowanie to wyraźne oznaczanie kodu, który może wydawać się niewłaściwy lub niepotrzebny. Z racji tego, że programy są zdarzeniowe, czasem zrobienie zwykłego przypisania powoduje szereg następstw, które mogą prowadzić do nietypowych rozwiązań, które - patrząc powierzchownie - są irracjonalne.
Czwarte zastosowanie, które gorąco polecam, to opisywanie klauzuli end bloków w taki sposób, aby jasne było jaki funkcjonalnie blok jest zamykamy. Ma to niebagatelne znaczenie w momencie, gdy bloki są długie, a nagle w jednym miejscu występuje szereg zamknięć kolejnych bloków. By nie pogubić się w tym i łatwo zorientować, gdzie ewentualnie dopisać potrzebny kod, należy właśnie opisywać zamknięcia bloków. Najczęściej sprowadza się to albo do opisu, albo do powtórzenia instrukcji inicjującej dany blok.
Poniższy kod prezentuje zastosowanie komentarzy we wszystkich wymienionych przypadkach:
function TfrmMain.VerifyData(const aName, aEmail: String; out aError: Byte): Boolean;
{ Weryfikuje poprawność otrzymanych danych i ustawia RadioButtony
Parametry:
aName - Imię i nazwisko
eEmail - Adres e-mail
Zwracane:
aError - kod błędu:
0 - bez błędów
1 - niepoprawne imie
2 - niepoprawny email
Zwraca:
True - wszystko OK}
var
cZnak: Char;
bJestMalpa: Boolean;
bJestKropkaZaMapla: Boolean;
begin
// sprawdzamy, czy podano i imię, i nazwisko:
if Pos(' ', aName) > 2 {imie musi mieć min. 2 znaki} then begin
Application.MessageBox( 'Nie podano imienia i nazwiska!',
PChar(Application.Title),
MB_ICONSTOP);
aError := 1;
Exit(False);
end; // if Pos(' ', aName) > 2
// sprawdzamy poprawność adresu e-mail:
bJestMalpa := False;
for cZnak in aEmail do begin
if cZnak = '@' then begin
if bJestMalpa then begin // już jedna jest!
Application.MessageBox( 'Adres e-mail zawiera więcej, niż jedno wystąpienie znaku @!',
PChar(Application.Title),
MB_ICONSTOP);
aError := 2;
Exit(False);
end else //dwie małpy
bJestMalpa := True;
end // cZnak = '@'
else if (cZnak = '.') and bJestMalpa then begin
bJestKropkaZaMapla := True;
Break; //Nie ma potrzeby sprawdzać dalej
end; // znak = '.'
end; //for cZnak in aEmail
if not bJestMalpa then begin
Application.MessageBox( 'Adres e-mail nie zawiera znaku @!',
PChar(Application.Title),
MB_ICONSTOP);
aError := 2;
Exit(False);
end //brak małpy
else if not bJestKropka then begin
Application.MessageBox( 'Adres e-mail nie zawiera poprawnej nazwy domeny!',
PChar(Application.Title),
MB_ICONSTOP);
aError := 2;
Exit(False);
end; //brak kropki
// wszystko ok, zmieniamy RadioButtony:
rbPrzesylanie.Checked := True;
rbWypelnianie.Checked := False; // te RadioButtony nie znajduja się na wspólnym panelu,
// więc ustawienie pierwszego nie wyłącza drugiego - trzeba samemu
Result := True;
end;
Podsumowanie
Stosowanie się do zasad podanych w tym poradniku z pewnością wpłynie pozytywnie na proces konserwacji kodu, ułatwi jego analizę w przyszłości nie tylko autorowi, ale także wszelkim osobom, którym kod będzie trzeba pokazać. Dobrze jest już jak najwcześniej zaczynając przygodę z programowanie wyrobić sobie pewne właściwe nawyki pisania czytelnego kodu, odnaleźć własny styl i stosować go w sposób jednolity do całego kodu. Problemem może być praca zespołowa, gdzie pewne charakterystyczne rozwiązania w kwestii czytelności kodu mogą (i powinny) być narzucone odgórnie. Jednak przestrzeganie reguł pozytywnie wpływa na czas potrzebny na czytanie i ponowne rozbieranie kodu na czynniki w celu jego modyfikacji, poprawy lub po prostu zrozumienia działania (gdy np. klient pyta się o szczegóły zachowania danej operacji).
Mam świadomość, że pisząc bardziej poważne kody nieraz pojawią się jeszcze inne, niewspomniane problemy, które związane będą bezpośrednio z czytelnością. Nie sposób jednak opisać wszystkie przypadki. Jednak mam nadzieję, że poradnik będzie dobrym początkiem dla rozpoczynających przygodę z programowaniem, a umiejętność zwrócenia uwagi w tych poruszonych kwestiach bez problemu pozwoli na tworzenia kolejnych, własnych konwencji i rozwiązań.
|